Introduction to R and RStudio
Overview
Teaching: 45 min
Exercises: 10 minQuestions
How to find your way around RStudio?
How to interact with R?
How to manage your environment?
How to install packages?
Objectives
Describe the purpose and use of each pane in the RStudio IDE
Locate buttons and options in the RStudio IDE
Define a variable
Assign data to a variable
Manage a workspace in an interactive R session
Use mathematical and comparison operators
Call functions
Manage packages
Motivation
Science is a multi-step process: once you’ve designed an experiment and collected data, the real fun begins! This lesson will teach you how to start this process using R and RStudio. We will begin with raw data, perform exploratory analyses, and learn how to plot results graphically. This example starts with a dataset from gapminder.org containing population information for many countries through time. Can you read the data into R? Can you plot the population for Senegal? Can you calculate the average income for countries on the continent of Asia? By the end of these lessons you will be able to do things like plot the populations for all of these countries in under a minute!
Before Starting The Workshop
Please ensure you have the latest version of R and RStudio installed on your machine. This is important, as some packages used in the workshop may not install correctly (or at all) if R is not up to date.
Introduction to RStudio
Welcome to the R portion of the Software Carpentry workshop.
Throughout this lesson, we’re going to teach you some of the fundamentals of the R language as well as some best practices for organizing code for scientific projects that will make your life easier.
We’ll be using RStudio: a free, open source R Integrated Development Environment (IDE). It provides a built-in editor, works on all platforms (including on servers) and provides many advantages such as integration with version control and project management.
Basic layout
When you first open RStudio, you will be greeted by three panels:
- The interactive R console/Terminal (entire left)
- Environment/History/Connections (tabbed in upper right)
- Files/Plots/Packages/Help/Viewer (tabbed in lower right)
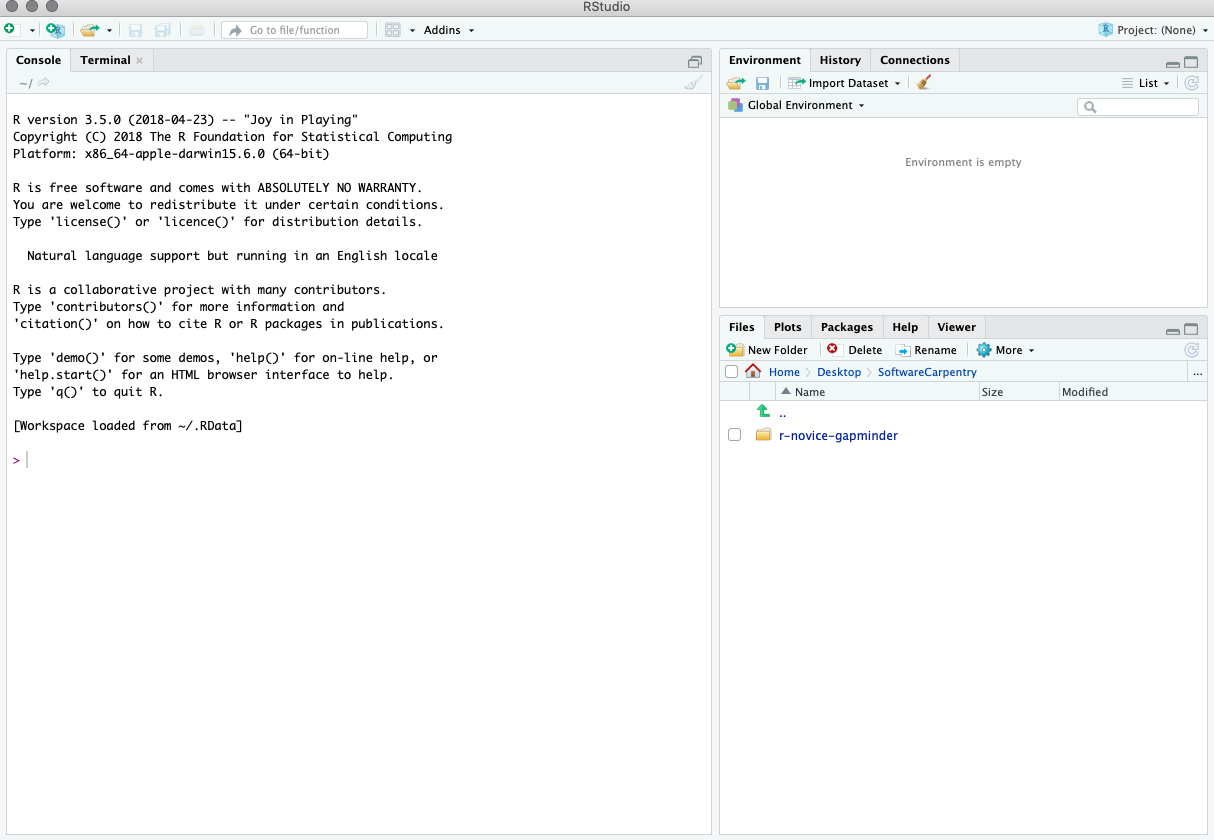
Once you open files, such as R scripts, an editor panel will also open in the top left.
Work flow within RStudio
There are two main ways one can work within RStudio:
- Test and play within the interactive R console then copy code into
a .R file to run later.
- This works well when doing small tests and initially starting off.
- It quickly becomes laborious
- Start writing in a .R file and use RStudio’s short cut keys for the Run command
to push the current line, selected lines or modified lines to the
interactive R console.
- This is a great way to start; all your code is saved for later
- You will be able to run the file you create from within RStudio
or using R’s
source()function.
Tip: Running segments of your code
RStudio offers you great flexibility in running code from within the editor window. There are buttons, menu choices, and keyboard shortcuts. To run the current line, you can
- click on the
Runbutton above the editor panel, or- select “Run Lines” from the “Code” menu, or
- hit Ctrl+Return in Windows or Linux or ⌘+Return on OS X. (This shortcut can also be seen by hovering the mouse over the button). To run a block of code, select it and then
Run. If you have modified a line of code within a block of code you have just run, there is no need to reselect the section andRun, you can use the next button along,Re-run the previous region. This will run the previous code block including the modifications you have made.
Introduction to R
Much of your time in R will be spent in the R interactive
console. This is where you will run all of your code, and can be a
useful environment to try out ideas before adding them to an R script
file. This console in RStudio is the same as the one you would get if
you typed in R in your command-line environment.
The first thing you will see in the R interactive session is a bunch of information, followed by a “>” and a blinking cursor. In many ways this is similar to the shell environment you learned about during the shell lessons: it operates on the same idea of a “Read, evaluate, print loop”: you type in commands, R tries to execute them, and then returns a result.
Using R as a calculator
The simplest thing you could do with R is to do arithmetic:
1 + 100
[1] 101
And R will print out the answer, with a preceding “[1]”. Don’t worry about this for now, we’ll explain that later. For now think of it as indicating output.
Like bash, if you type in an incomplete command, R will wait for you to complete it:
> 1 +
+
Any time you hit return and the R session shows a “+” instead of a “>”, it means it’s waiting for you to complete the command. If you want to cancel a command you can hit Esc and RStudio will give you back the “>” prompt.
Tip: Canceling commands
If you’re using R from the command line instead of from within RStudio, you need to use Ctrl+C instead of Esc to cancel the command. This applies to Mac users as well!
Canceling a command isn’t only useful for killing incomplete commands: you can also use it to tell R to stop running code (for example if it’s taking much longer than you expect), or to get rid of the code you’re currently writing.
When using R as a calculator, the order of operations is the same as you would have learned back in school.
From highest to lowest precedence:
- Parentheses:
(,) - Exponents:
^or** - Multiply:
* - Divide:
/ - Add:
+ - Subtract:
-
3 + 5 * 2
[1] 13
Use parentheses to group operations in order to force the order of evaluation if it differs from the default, or to make clear what you intend.
(3 + 5) * 2
[1] 16
This can get unwieldy when not needed, but clarifies your intentions. Remember that others may later read your code.
(3 + (5 * (2 ^ 2))) # hard to read
3 + 5 * 2 ^ 2 # clear, if you remember the rules
3 + 5 * (2 ^ 2) # if you forget some rules, this might help
The text after each line of code is called a
“comment”. Anything that follows after the hash (or octothorpe) symbol
# is ignored by R when it executes code.
Really small or large numbers get a scientific notation:
2/10000
[1] 2e-04
Which is shorthand for “multiplied by 10^XX”. So 2e-4
is shorthand for 2 * 10^(-4).
You can write numbers in scientific notation too:
5e3 # Note the lack of minus here
[1] 5000
Mathematical functions
R has many built in mathematical functions. To call a function, we can type its name, followed by open and closing parentheses. Anything we type inside the parentheses is called the function’s arguments:
sin(1) # trigonometry functions
[1] 0.841471
log(1) # natural logarithm
[1] 0
log10(10) # base-10 logarithm
[1] 1
exp(0.5) # e^(1/2)
[1] 1.648721
Don’t worry about trying to remember every function in R. You can look them up on Google, or if you can remember the start of the function’s name, use the tab completion in RStudio.
This is one advantage that RStudio has over R on its own, it has auto-completion abilities that allow you to more easily look up functions, their arguments, and the values that they take.
Typing a ? before the name of a command will open the help page
for that command. When using RStudio, this will open the ‘Help’ pane;
if using R in the terminal, the help page will open in your browser.
The help page will include a detailed description of the command and
how it works. Scrolling to the bottom of the help page will usually
show a collection of code examples which illustrate command usage.
We’ll go through an example later.
Comparing things
We can also do comparisons in R:
1 == 1 # equality (note two equals signs, read as "is equal to")
[1] TRUE
1 != 2 # inequality (read as "is not equal to")
[1] TRUE
1 < 2 # less than
[1] TRUE
1 <= 1 # less than or equal to
[1] TRUE
1 > 0 # greater than
[1] TRUE
1 >= -9 # greater than or equal to
[1] TRUE
Tip: Comparing Numbers
A word of warning about comparing numbers: you should never use
==to compare two numbers unless they are integers (a data type which can specifically represent only whole numbers).Computers may only represent decimal numbers with a certain degree of precision, so two numbers which look the same when printed out by R, may actually have different underlying representations and therefore be different by a small margin of error (called Machine numeric tolerance).
Instead you should use the
all.equalfunction.Further reading: http://floating-point-gui.de/
Variables and assignment
We can store values in variables using the assignment operator <-, like this:
x <- 1/40
Notice that assignment does not print a value. Instead, we stored it for later
in something called a variable. x now contains the value 0.025:
x
[1] 0.025
More precisely, the stored value is a decimal approximation of this fraction called a floating point number.
Look for the Environment tab in the top right panel of RStudio, and you will see that x and its value
have appeared. Our variable x can be used in place of a number in any calculation that expects a number:
log(x)
[1] -3.688879
Notice also that variables can be reassigned:
x <- 100
x used to contain the value 0.025 and now it has the value 100.
Assignment values can contain the variable being assigned to:
x <- x + 1 #notice how RStudio updates its description of x on the top right tab
y <- x * 2
The right hand side of the assignment can be any valid R expression. The right hand side is fully evaluated before the assignment occurs.
Variable names can contain letters, numbers, underscores and periods but no spaces. They must start with a letter or a period followed by a letter (they cannot start with a number nor an underscore). Variables beginning with a period are hidden variables. Different people use different conventions for long variable names, these include
- periods.between.words
- underscores_between_words
- camelCaseToSeparateWords
What you use is up to you, but be consistent.
It is also possible to use the = operator for assignment:
x = 1/40
But this is much less common among R users. The most important thing is to
be consistent with the operator you use. There are occasionally places
where it is less confusing to use <- than =, and it is the most common
symbol used in the community. So the recommendation is to use <-.
Challenge 1
Which of the following are valid R variable names?
min_height max.height _age .mass MaxLength min-length 2widths celsius2kelvinSolution to challenge 1
The following can be used as R variables:
min_height max.height MaxLength celsius2kelvinThe following creates a hidden variable:
.massThe following will not be able to be used to create a variable
_age min-length 2widths
Vectorization
One final thing to be aware of is that R is vectorized, meaning that variables and functions can have vectors as values. In contrast to physics and mathematics, a vector in R describes a set of values in a certain order of the same data type. For example
1:5
[1] 1 2 3 4 5
2^(1:5)
[1] 2 4 8 16 32
x <- 1:5
2^x
[1] 2 4 8 16 32
This is incredibly powerful; we will discuss this further in an upcoming lesson.
Managing your environment
There are a few useful commands you can use to interact with the R session.
ls will list all of the variables and functions stored in the global environment
(your working R session):
ls()
[1] "args" "dest_md" "op" "src_rmd" "x" "y"
Tip: hidden objects
Like in the shell,
lswill hide any variables or functions starting with a “.” by default. To list all objects, typels(all.names=TRUE)instead
Note here that we didn’t give any arguments to ls, but we still
needed to give the parentheses to tell R to call the function.
If we type ls by itself, R prints a bunch of code instead of a listing of objects.
ls
function (name, pos = -1L, envir = as.environment(pos), all.names = FALSE,
pattern, sorted = TRUE)
{
if (!missing(name)) {
pos <- tryCatch(name, error = function(e) e)
if (inherits(pos, "error")) {
name <- substitute(name)
if (!is.character(name))
name <- deparse(name)
warning(gettextf("%s converted to character string",
sQuote(name)), domain = NA)
pos <- name
}
}
all.names <- .Internal(ls(envir, all.names, sorted))
if (!missing(pattern)) {
if ((ll <- length(grep("[", pattern, fixed = TRUE))) &&
ll != length(grep("]", pattern, fixed = TRUE))) {
if (pattern == "[") {
pattern <- "\\["
warning("replaced regular expression pattern '[' by '\\\\['")
}
else if (length(grep("[^\\\\]\\[<-", pattern))) {
pattern <- sub("\\[<-", "\\\\\\[<-", pattern)
warning("replaced '[<-' by '\\\\[<-' in regular expression pattern")
}
}
grep(pattern, all.names, value = TRUE)
}
else all.names
}
<bytecode: 0x559cb3713ef0>
<environment: namespace:base>
What’s going on here?
Like everything in R, ls is the name of an object, and entering the name of
an object by itself prints the contents of the object. The object x that we
created earlier contains 1, 2, 3, 4, 5:
x
[1] 1 2 3 4 5
The object ls contains the R code that makes the ls function work! We’ll talk
more about how functions work and start writing our own later.
You can use rm to delete objects you no longer need:
rm(x)
If you have lots of things in your environment and want to delete all of them,
you can pass the results of ls to the rm function:
rm(list = ls())
In this case we’ve combined the two. Like the order of operations, anything inside the innermost parentheses is evaluated first, and so on.
In this case we’ve specified that the results of ls should be used for the
list argument in rm. When assigning values to arguments by name, you must
use the = operator!!
If instead we use <-, there will be unintended side effects, or you may get an error message:
rm(list <- ls())
Error in rm(list <- ls()): ... must contain names or character strings
Tip: Warnings vs. Errors
Pay attention when R does something unexpected! Errors, like above, are thrown when R cannot proceed with a calculation. Warnings on the other hand usually mean that the function has run, but it probably hasn’t worked as expected.
In both cases, the message that R prints out usually give you clues how to fix a problem.
R Packages
It is possible to add functions to R by writing a package, or by obtaining a package written by someone else. As of this writing, there are over 10,000 packages available on CRAN (the comprehensive R archive network). R and RStudio have functionality for managing packages:
- You can see what packages are installed by typing
installed.packages() - You can install packages by typing
install.packages("packagename"), wherepackagenameis the package name, in quotes. - You can update installed packages by typing
update.packages() - You can remove a package with
remove.packages("packagename") - You can make a package available for use with
library(packagename)
Packages can also be viewed, loaded, and detached in the Packages tab of the lower right panel in RStudio. Clicking on this tab will display all of the installed packages with a checkbox next to them. If the box next to a package name is checked, the package is loaded and if it is empty, the package is not loaded. Click an empty box to load that package and click a checked box to detach that package.
Packages can be installed and updated from the Package tab with the Install and Update buttons at the top of the tab.
Challenge 2
What will be the value of each variable after each statement in the following program?
mass <- 47.5 age <- 122 mass <- mass * 2.3 age <- age - 20Solution to challenge 2
mass <- 47.5This will give a value of 47.5 for the variable mass
age <- 122This will give a value of 122 for the variable age
mass <- mass * 2.3This will multiply the existing value of 47.5 by 2.3 to give a new value of 109.25 to the variable mass.
age <- age - 20This will subtract 20 from the existing value of 122 to give a new value of 102 to the variable age.
Challenge 3
Run the code from the previous challenge, and write a command to compare mass to age. Is mass larger than age?
Solution to challenge 3
One way of answering this question in R is to use the
>to set up the following:mass > age[1] TRUEThis should yield a boolean value of TRUE since 109.25 is greater than 102.
Challenge 4
Clean up your working environment by deleting the mass and age variables.
Solution to challenge 4
We can use the
rmcommand to accomplish this taskrm(age, mass)
Challenge 5
Install the following packages:
ggplot2,plyr,gapminderSolution to challenge 5
We can use the
install.packages()command to install the required packages.install.packages("ggplot2") install.packages("plyr") install.packages("gapminder")An alternate solution, to install multiple packages with a single
install.packages()command is:install.packages(c("ggplot2", "plyr", "gapminder"))
Key Points
Use RStudio to write and run R programs.
R has the usual arithmetic operators and mathematical functions.
Use
<-to assign values to variables.Use
ls()to list the variables in a program.Use
rm()to delete objects in a program.Use
install.packages()to install packages (libraries).
Project Management With RStudio
Overview
Teaching: 20 min
Exercises: 10 minQuestions
How can I manage my projects in R?
Objectives
Create self-contained projects in RStudio
Introduction
The scientific process is naturally incremental, and many projects start life as random notes, some code, then a manuscript, and eventually everything is a bit mixed together.
Managing your projects in a reproducible fashion doesn't just make your science reproducible, it makes your life easier.
— Vince Buffalo (@vsbuffalo) April 15, 2013
Most people tend to organize their projects like this:
There are many reasons why we should ALWAYS avoid this:
- It is really hard to tell which version of your data is the original and which is the modified;
- It gets really messy because it mixes files with various extensions together;
- It probably takes you a lot of time to actually find things, and relate the correct figures to the exact code that has been used to generate it;
A good project layout will ultimately make your life easier:
- It will help ensure the integrity of your data;
- It makes it simpler to share your code with someone else (a lab-mate, collaborator, or supervisor);
- It allows you to easily upload your code with your manuscript submission;
- It makes it easier to pick the project back up after a break.
A possible solution
Fortunately, there are tools and packages which can help you manage your work effectively.
One of the most powerful and useful aspects of RStudio is its project management functionality. We’ll be using this today to create a self-contained, reproducible project.
Challenge 1: Creating a self-contained project
We’re going to create a new project in RStudio:
- Click the “File” menu button, then “New Project”.
- Click “New Directory”.
- Click “New Project”.
- Type in the name of the directory to store your project, e.g. “my_project”.
- If available, select the checkbox for “Create a git repository.”
- Click the “Create Project” button.
The simplest way to open an RStudio project once it has been created is to click
through your file system to get to the directory where it was saved and double
click on the .Rproj file. This will open RStudio and start your R session in the
same directory as the .Rproj file. All your data, plots and scripts will now be
relative to the project directory. RStudio projects have the added benefit of
allowing you to open multiple projects at the same time each open to its own
project directory. This allows you to keep multiple projects open without them
interfering with each other.
Challenge 2: Opening an RStudio project through the file system
- Exit RStudio.
- Navigate to the directory where you created a project in Challenge 1.
- Double click on the
.Rprojfile in that directory.
Best practices for project organization
Although there is no “best” way to lay out a project, there are some general principles to adhere to that will make project management easier:
Treat data as read only
This is probably the most important goal of setting up a project. Data is typically time consuming and/or expensive to collect. Working with them interactively (e.g., in Excel) where they can be modified means you are never sure of where the data came from, or how it has been modified since collection. It is therefore a good idea to treat your data as “read-only”.
Data Cleaning
In many cases your data will be “dirty”: it will need significant preprocessing to get into a format R (or any other programming language) will find useful. This task is sometimes called “data munging”. Storing these scripts in a separate folder, and creating a second “read-only” data folder to hold the “cleaned” data sets can prevent confusion between the two sets.
Treat generated output as disposable
Anything generated by your scripts should be treated as disposable: it should all be able to be regenerated from your scripts.
There are lots of different ways to manage this output. Having an output folder with different sub-directories for each separate analysis makes it easier later. Since many analyses are exploratory and don’t end up being used in the final project, and some of the analyses get shared between projects.
Tip: Good Enough Practices for Scientific Computing
Good Enough Practices for Scientific Computing gives the following recommendations for project organization:
- Put each project in its own directory, which is named after the project.
- Put text documents associated with the project in the
docdirectory.- Put raw data and metadata in the
datadirectory, and files generated during cleanup and analysis in aresultsdirectory.- Put source for the project’s scripts and programs in the
srcdirectory, and programs brought in from elsewhere or compiled locally in thebindirectory.- Name all files to reflect their content or function.
Separate function definition and application
One of the more effective ways to work with R is to start by writing the code you want to run directly in a .R script, and then running the selected lines (either using the keyboard shortcuts in RStudio or clicking the “Run” button) in the interactive R console.
When your project is in its early stages, the initial .R script file usually contains many lines of directly executed code. As it matures, reusable chunks get pulled into their own functions. It’s a good idea to separate these functions into two separate folders; one to store useful functions that you’ll reuse across analyses and projects, and one to store the analysis scripts.
Tip: avoiding duplication
You may find yourself using data or analysis scripts across several projects. Typically you want to avoid duplication to save space and avoid having to make updates to code in multiple places.
In this case, making “symbolic links”, which are essentially shortcuts to files somewhere else on a filesystem, can let you use existing code without having to move or copy it. Plus, any changes made to that code will only have to be made once.
On Linux and OS X you can use the
ln -scommand, and on Windows you can either create a shortcut or use themklinkcommand from the windows terminal.
Save the data in the data directory
Now we have a good directory structure we will now place/save the data file in the data/ directory.
Challenge 3
Download the gapminder data from here.
- Download the file (right mouse click on the link above -> “Save link as” / “Save file as”, or click on the link and after the page loads, press Ctrl+S or choose File -> “Save page as”)
- Make sure it’s saved under the name
gapminder_data.csv- Save the file in the
data/folder within your project.We will load and inspect these data later.
Challenge 4
It is useful to get some general idea about the dataset, directly from the command line, before loading it into R. Understanding the dataset better will come in handy when making decisions on how to load it in R. Use the command-line shell to answer the following questions:
- What is the size of the file?
- How many rows of data does it contain?
- What kinds of values are stored in this file?
Solution to Challenge 4
By running these commands in the shell:
ls -lh data/gapminder_data.csv-rw-r--r-- 1 runner docker 80K Jul 8 22:13 data/gapminder_data.csvThe file size is 80K.
wc -l data/gapminder_data.csv1705 data/gapminder_data.csvThere are 1705 lines. The data looks like:
head data/gapminder_data.csvcountry,year,pop,continent,lifeExp,gdpPercap Afghanistan,1952,8425333,Asia,28.801,779.4453145 Afghanistan,1957,9240934,Asia,30.332,820.8530296 Afghanistan,1962,10267083,Asia,31.997,853.10071 Afghanistan,1967,11537966,Asia,34.02,836.1971382 Afghanistan,1972,13079460,Asia,36.088,739.9811058 Afghanistan,1977,14880372,Asia,38.438,786.11336 Afghanistan,1982,12881816,Asia,39.854,978.0114388 Afghanistan,1987,13867957,Asia,40.822,852.3959448 Afghanistan,1992,16317921,Asia,41.674,649.3413952
Tip: command line in RStudio
The Terminal tab in the console pane provides a convenient place directly within RStudio to interact directly with the command line.
Version Control
It is important to use version control with projects. Go here for a good lesson which describes using Git with RStudio.
Key Points
Use RStudio to create and manage projects with consistent layout.
Treat raw data as read-only.
Treat generated output as disposable.
Separate function definition and application.
Seeking Help
Overview
Teaching: 10 min
Exercises: 10 minQuestions
How can I get help in R?
Objectives
To be able read R help files for functions and special operators.
To be able to use CRAN task views to identify packages to solve a problem.
To be able to seek help from your peers.
Reading Help files
R, and every package, provide help files for functions. The general syntax to search for help on any function, “function_name”, from a specific function that is in a package loaded into your namespace (your interactive R session):
?function_name
help(function_name)
This will load up a help page in RStudio (or as plain text in R by itself).
Each help page is broken down into sections:
- Description: An extended description of what the function does.
- Usage: The arguments of the function and their default values.
- Arguments: An explanation of the data each argument is expecting.
- Details: Any important details to be aware of.
- Value: The data the function returns.
- See Also: Any related functions you might find useful.
- Examples: Some examples for how to use the function.
Different functions might have different sections, but these are the main ones you should be aware of.
Tip: Running Examples
From within the function help page, you can highlight code in the Examples and hit Ctrl+Return to run it in RStudio console. This is gives you a quick way to get a feel for how a function works.
Tip: Reading help files
One of the most daunting aspects of R is the large number of functions available. It would be prohibitive, if not impossible to remember the correct usage for every function you use. Luckily, the help files mean you don’t have to!
Special Operators
To seek help on special operators, use quotes or backticks:
?"<-"
?`<-`
Getting help on packages
Many packages come with “vignettes”: tutorials and extended example documentation.
Without any arguments, vignette() will list all vignettes for all installed packages;
vignette(package="package-name") will list all available vignettes for
package-name, and vignette("vignette-name") will open the specified vignette.
If a package doesn’t have any vignettes, you can usually find help by typing
help("package-name").
RStudio also has a set of excellent cheatsheets for many packages.
When you kind of remember the function
If you’re not sure what package a function is in, or how it’s specifically spelled you can do a fuzzy search:
??function_name
A fuzzy search is when you search for an approximate string match. For example, you may remember that the function to set your working directory includes “set” in its name. You can do a fuzzy search to help you identify the function:
??set
When you have no idea where to begin
If you don’t know what function or package you need to use CRAN Task Views is a specially maintained list of packages grouped into fields. This can be a good starting point.
When your code doesn’t work: seeking help from your peers
If you’re having trouble using a function, 9 times out of 10,
the answers you are seeking have already been answered on
Stack Overflow. You can search using
the [r] tag. Please make sure to see their page on
how to ask a good question.
If you can’t find the answer, there are a few useful functions to help you ask a question from your peers:
?dput
Will dump the data you’re working with into a format so that it can be copy and pasted by anyone else into their R session.
sessionInfo()
R version 4.1.0 (2021-05-18)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.2 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] knitr_1.33
loaded via a namespace (and not attached):
[1] compiler_4.1.0 magrittr_2.0.1 tools_4.1.0 stringi_1.6.2 stringr_1.4.0
[6] xfun_0.24 evaluate_0.14
Will print out your current version of R, as well as any packages you have loaded. This can be useful for others to help reproduce and debug your issue.
Challenge 1
Look at the help for the
cfunction. What kind of vector do you expect you will create if you evaluate the following:c(1, 2, 3) c('d', 'e', 'f') c(1, 2, 'f')Solution to Challenge 1
The
c()function creates a vector, in which all elements are the same type. In the first case, the elements are numeric, in the second, they are characters, and in the third they are characters: the numeric values are “coerced” to be characters.
Challenge 2
Look at the help for the
pastefunction. You’ll need to use this later. What is the difference between thesepandcollapsearguments?Solution to Challenge 2
To look at the help for the
paste()function, use:help("paste") ?pasteThe difference between
sepandcollapseis a little tricky. Thepastefunction accepts any number of arguments, each of which can be a vector of any length. Thesepargument specifies the string used between concatenated terms — by default, a space. The result is a vector as long as the longest argument supplied topaste. In contrast,collapsespecifies that after concatenation the elements are collapsed together using the given separator, the result being a single string. e.g.paste(c("a","b"), "c")[1] "a c" "b c"paste(c("a","b"), "c", sep = ",")[1] "a,c" "b,c"paste(c("a","b"), "c", collapse = "|")[1] "a c|b c"paste(c("a","b"), "c", sep = ",", collapse = "|")[1] "a,c|b,c"(For more information, scroll to the bottom of the
?pastehelp page and look at the examples, or tryexample('paste').)
Challenge 3
Use help to find a function (and its associated parameters) that you could use to load data from a tabular file in which columns are delimited with “\t” (tab) and the decimal point is a “.” (period). This check for decimal separator is important, especially if you are working with international colleagues, because different countries have different conventions for the decimal point (i.e. comma vs period). hint: use
??"read table"to look up functions related to reading in tabular data.Solution to Challenge 3
The standard R function for reading tab-delimited files with a period decimal separator is read.delim(). You can also do this with
read.table(file, sep="\t")(the period is the default decimal separator forread.table(), although you may have to change thecomment.charargument as well if your data file contains hash (#) characters
Other ports of call
Key Points
Use
help()to get online help in R.
Data Structures
Overview
Teaching: 40 min
Exercises: 15 minQuestions
How can I read data in R?
What are the basic data types in R?
How do I represent categorical information in R?
Objectives
To be able to identify the 5 main data types.
To begin exploring data frames, and understand how they are related to vectors, factors and lists.
To be able to ask questions from R about the type, class, and structure of an object.
One of R’s most powerful features is its ability to deal with tabular data -
such as you may already have in a spreadsheet or a CSV file. Let’s start by
making a toy dataset in your data/ directory, called feline-data.csv:
cats <- data.frame(coat = c("calico", "black", "tabby"),
weight = c(2.1, 5.0, 3.2),
likes_string = c(1, 0, 1))
write.csv(x = cats, file = "data/feline-data.csv", row.names = FALSE)
The contents of the new file, feline-data.csv:
coat,weight,likes_string
calico,2.1,1
black,5.0,0
tabby,3.2,1
Tip: Editing Text files in R
Alternatively, you can create
data/feline-data.csvusing a text editor (Nano), or within RStudio with the File -> New File -> Text File menu item.
We can load this into R via the following:
cats <- read.csv(file = "data/feline-data.csv", stringsAsFactors = TRUE)
cats
coat weight likes_string
1 calico 2.1 1
2 black 5.0 0
3 tabby 3.2 1
The read.table function is used for reading in tabular data stored in a text
file where the columns of data are separated by punctuation characters such as
CSV files (csv = comma-separated values). Tabs and commas are the most common
punctuation characters used to separate or delimit data points in csv files.
For convenience R provides 2 other versions of read.table. These are: read.csv
for files where the data are separated with commas and read.delim for files
where the data are separated with tabs. Of these three functions read.csv is
the most commonly used. If needed it is possible to override the default
delimiting punctuation marks for both read.csv and read.delim.
We can begin exploring our dataset right away, pulling out columns by specifying
them using the $ operator:
cats$weight
[1] 2.1 5.0 3.2
cats$coat
[1] calico black tabby
Levels: black calico tabby
We can do other operations on the columns:
## Say we discovered that the scale weighs two Kg light:
cats$weight + 2
[1] 4.1 7.0 5.2
paste("My cat is", cats$coat)
[1] "My cat is calico" "My cat is black" "My cat is tabby"
But what about
cats$weight + cats$coat
Warning in Ops.factor(cats$weight, cats$coat): '+' not meaningful for factors
[1] NA NA NA
Understanding what happened here is key to successfully analyzing data in R.
Data Types
If you guessed that the last command will return an error because 2.1 plus
"black" is nonsense, you’re right - and you already have some intuition for an
important concept in programming called data types. We can ask what type of
data something is:
typeof(cats$weight)
[1] "double"
There are 5 main types: double, integer, complex, logical and character.
typeof(3.14)
[1] "double"
typeof(1L) # The L suffix forces the number to be an integer, since by default R uses float numbers
[1] "integer"
typeof(1+1i)
[1] "complex"
typeof(TRUE)
[1] "logical"
typeof('banana')
[1] "character"
No matter how complicated our analyses become, all data in R is interpreted as one of these basic data types. This strictness has some really important consequences.
A user has added details of another cat. This information is in the file
data/feline-data_v2.csv.
file.show("data/feline-data_v2.csv")
coat,weight,likes_string
calico,2.1,1
black,5.0,0
tabby,3.2,1
tabby,2.3 or 2.4,1
Load the new cats data like before, and check what type of data we find in the
weight column:
cats <- read.csv(file="data/feline-data_v2.csv", stringsAsFactors = TRUE)
typeof(cats$weight)
[1] "integer"
Oh no, our weights aren’t the double type anymore! If we try to do the same math we did on them before, we run into trouble:
cats$weight + 2
Warning in Ops.factor(cats$weight, 2): '+' not meaningful for factors
[1] NA NA NA NA
What happened?
The cats data we are working with is something called a data frame. Data frames
are one of the most common and versatile types of data structures we will work with in R.
In this example, the columns that make up the data frame cannot be composed of different data types.
In this case, R does not read everything in the data frame as a double, therefore the entire
column data type changes to something that is suitable for everything in the column.
When R reads a csv file, it reads it in as a data frame. Thus, when we loaded the cats
csv file, it is stored as a data frame. We can check this by using the function class().
class(cats)
[1] "data.frame"
Data frames are composed of rows and columns, where each column has the same number of rows. Different columns in a data frame can be made up of different data types (this is what makes them so versatile), but everything in a given column needs to be the same type (e.g., vector, factor, or list).
Let’s explore more about different data structures and how they behave. For now, let’s remove that extra line from our cats data and reload it, while we investigate this behavior further:
feline-data.csv:
coat,weight,likes_string
calico,2.1,1
black,5.0,0
tabby,3.2,1
And back in RStudio:
cats <- read.csv(file="data/feline-data.csv", stringsAsFactors = TRUE)
Vectors and Type Coercion
To better understand this behavior, let’s meet another of the data structures: the vector.
my_vector <- vector(length = 3)
my_vector
[1] FALSE FALSE FALSE
A vector in R is essentially an ordered list of things, with the special
condition that everything in the vector must be the same basic data type. If
you don’t choose the datatype, it’ll default to logical; or, you can declare
an empty vector of whatever type you like.
another_vector <- vector(mode='character', length=3)
another_vector
[1] "" "" ""
You can check if something is a vector:
str(another_vector)
chr [1:3] "" "" ""
The somewhat cryptic output from this command indicates the basic data type
found in this vector - in this case chr, character; an indication of the
number of things in the vector - actually, the indexes of the vector, in this
case [1:3]; and a few examples of what’s actually in the vector - in this case
empty character strings. If we similarly do
str(cats$weight)
num [1:3] 2.1 5 3.2
we see that cats$weight is a vector, too - the columns of data we load into R
data.frames are all vectors, and that’s the root of why R forces everything in
a column to be the same basic data type.
Discussion 1
Why is R so opinionated about what we put in our columns of data? How does this help us?
Discussion 1
By keeping everything in a column the same, we allow ourselves to make simple assumptions about our data; if you can interpret one entry in the column as a number, then you can interpret all of them as numbers, so we don’t have to check every time. This consistency is what people mean when they talk about clean data; in the long run, strict consistency goes a long way to making our lives easier in R.
You can also make vectors with explicit contents with the combine function:
combine_vector <- c(2,6,3)
combine_vector
[1] 2 6 3
Given what we’ve learned so far, what do you think the following will produce?
quiz_vector <- c(2,6,'3')
This is something called type coercion, and it is the source of many surprises and the reason why we need to be aware of the basic data types and how R will interpret them. When R encounters a mix of types (here numeric and character) to be combined into a single vector, it will force them all to be the same type. Consider:
coercion_vector <- c('a', TRUE)
coercion_vector
[1] "a" "TRUE"
another_coercion_vector <- c(0, TRUE)
another_coercion_vector
[1] 0 1
The coercion rules go: logical -> integer -> numeric -> complex ->
character, where -> can be read as are transformed into. You can try to
force coercion against this flow using the as. functions:
character_vector_example <- c('0','2','4')
character_vector_example
[1] "0" "2" "4"
character_coerced_to_numeric <- as.numeric(character_vector_example)
character_coerced_to_numeric
[1] 0 2 4
numeric_coerced_to_logical <- as.logical(character_coerced_to_numeric)
numeric_coerced_to_logical
[1] FALSE TRUE TRUE
As you can see, some surprising things can happen when R forces one basic data type into another! Nitty-gritty of type coercion aside, the point is: if your data doesn’t look like what you thought it was going to look like, type coercion may well be to blame; make sure everything is the same type in your vectors and your columns of data.frames, or you will get nasty surprises!
But coercion can also be very useful! For example, in our cats data
likes_string is numeric, but we know that the 1s and 0s actually represent
TRUE and FALSE (a common way of representing them). We should use the
logical datatype here, which has two states: TRUE or FALSE, which is
exactly what our data represents. We can ‘coerce’ this column to be logical by
using the as.logical function:
cats$likes_string
[1] 1 0 1
cats$likes_string <- as.logical(cats$likes_string)
cats$likes_string
[1] TRUE FALSE TRUE
The combine function, c(), will also append things to an existing vector:
ab_vector <- c('a', 'b')
ab_vector
[1] "a" "b"
combine_example <- c(ab_vector, 'SWC')
combine_example
[1] "a" "b" "SWC"
You can also make series of numbers:
mySeries <- 1:10
mySeries
[1] 1 2 3 4 5 6 7 8 9 10
seq(10)
[1] 1 2 3 4 5 6 7 8 9 10
seq(1,10, by=0.1)
[1] 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4
[16] 2.5 2.6 2.7 2.8 2.9 3.0 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9
[31] 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5.0 5.1 5.2 5.3 5.4
[46] 5.5 5.6 5.7 5.8 5.9 6.0 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9
[61] 7.0 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8.0 8.1 8.2 8.3 8.4
[76] 8.5 8.6 8.7 8.8 8.9 9.0 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9
[91] 10.0
We can ask a few questions about vectors:
sequence_example <- seq(10)
head(sequence_example, n=2)
[1] 1 2
tail(sequence_example, n=4)
[1] 7 8 9 10
length(sequence_example)
[1] 10
class(sequence_example)
[1] "integer"
typeof(sequence_example)
[1] "integer"
Finally, you can give names to elements in your vector:
my_example <- 5:8
names(my_example) <- c("a", "b", "c", "d")
my_example
a b c d
5 6 7 8
names(my_example)
[1] "a" "b" "c" "d"
Challenge 1
Start by making a vector with the numbers 1 through 26. Multiply the vector by 2, and give the resulting vector names A through Z (hint: there is a built in vector called
LETTERS)Solution to Challenge 1
x <- 1:26 x <- x * 2 names(x) <- LETTERS
Data Frames
We said that columns in data.frames were vectors:
str(cats$weight)
num [1:3] 2.1 5 3.2
str(cats$likes_string)
logi [1:3] TRUE FALSE TRUE
These make sense. But what about
str(cats$coat)
Factor w/ 3 levels "black","calico",..: 2 1 3
Tip: Renaming data frame columns
Data frames have column names, which can be accessed with the
names()function.names(cats)[1] "coat" "weight" "likes_string"If you want to rename the second column of
cats, you can assign a new name to the second element ofnames(cats).names(cats)[2] <- "weight_kg" catscoat weight_kg likes_string 1 calico 2.1 TRUE 2 black 5.0 FALSE 3 tabby 3.2 TRUE
Factors
Another important data structure is called a factor. Factors usually look like character data, but are typically used to represent categorical information. For example, let’s make a vector of strings labelling cat colorations for all the cats in our study:
coats <- c('tabby', 'tortoiseshell', 'tortoiseshell', 'black', 'tabby')
coats
[1] "tabby" "tortoiseshell" "tortoiseshell" "black"
[5] "tabby"
str(coats)
chr [1:5] "tabby" "tortoiseshell" "tortoiseshell" "black" "tabby"
We can turn a vector into a factor like so:
CATegories <- factor(coats)
class(CATegories)
[1] "factor"
str(CATegories)
Factor w/ 3 levels "black","tabby",..: 2 3 3 1 2
Now R has noticed that there are three possible categories in our data - but it also did something surprising; instead of printing out the strings we gave it, we got a bunch of numbers instead. R has replaced our human-readable categories with numbered indices under the hood, this is necessary as many statistical calculations utilise such numerical representations for categorical data:
typeof(coats)
[1] "character"
typeof(CATegories)
[1] "integer"
Challenge 2
Is there a factor in our
catsdata.frame? what is its name? Try using?read.csvto figure out how to keep text columns as character vectors instead of factors; then write a command or two to show that the factor incatsis actually a character vector when loaded in this way.Solution to Challenge 2
One solution is use the argument
stringAsFactors:cats <- read.csv(file="data/feline-data.csv", stringsAsFactors=FALSE) str(cats$coat)Another solution is use the argument
colClassesthat allow finer control.cats <- read.csv(file="data/feline-data.csv", colClasses=c(NA, NA, "character")) str(cats$coat)Note: new students find the help files difficult to understand; make sure to let them know that this is typical, and encourage them to take their best guess based on semantic meaning, even if they aren’t sure.
In modelling functions, it’s important to know what the baseline levels are. This is assumed to be the first factor, but by default factors are labelled in alphabetical order. You can change this by specifying the levels:
mydata <- c("case", "control", "control", "case")
factor_ordering_example <- factor(mydata, levels = c("control", "case"))
str(factor_ordering_example)
Factor w/ 2 levels "control","case": 2 1 1 2
In this case, we’ve explicitly told R that “control” should be represented by 1, and “case” by 2. This designation can be very important for interpreting the results of statistical models!
Lists
Another data structure you’ll want in your bag of tricks is the list. A list
is simpler in some ways than the other types, because you can put anything you
want in it. Remember everything in the vector must be the same basic data type,
but a list can have different data types:
list_example <- list(1, "a", TRUE, 1+4i)
list_example
[[1]]
[1] 1
[[2]]
[1] "a"
[[3]]
[1] TRUE
[[4]]
[1] 1+4i
another_list <- list(title = "Numbers", numbers = 1:10, data = TRUE )
another_list
$title
[1] "Numbers"
$numbers
[1] 1 2 3 4 5 6 7 8 9 10
$data
[1] TRUE
We can now understand something a bit surprising in our data.frame; what happens if we run:
typeof(cats)
[1] "list"
We see that data.frames look like lists ‘under the hood’ - this is because a
data.frame is really a list of vectors and factors, as they have to be - in
order to hold those columns that are a mix of vectors and factors, the
data.frame needs something a bit more flexible than a vector to put all the
columns together into a familiar table. In other words, a data.frame is a
special list in which all the vectors must have the same length.
In our cats example, we have an integer, a double and a logical variable. As
we have seen already, each column of data.frame is a vector.
cats$coat
[1] calico black tabby
Levels: black calico tabby
cats[,1]
[1] calico black tabby
Levels: black calico tabby
typeof(cats[,1])
[1] "integer"
str(cats[,1])
Factor w/ 3 levels "black","calico",..: 2 1 3
Each row is an observation of different variables, itself a data.frame, and thus can be composed of elements of different types.
cats[1,]
coat weight likes_string
1 calico 2.1 1
typeof(cats[1,])
[1] "list"
str(cats[1,])
'data.frame': 1 obs. of 3 variables:
$ coat : Factor w/ 3 levels "black","calico",..: 2
$ weight : num 2.1
$ likes_string: num 1
Challenge 3
There are several subtly different ways to call variables, observations and elements from data.frames:
cats[1]cats[[1]]cats$coatcats["coat"]cats[1, 1]cats[, 1]cats[1, ]Try out these examples and explain what is returned by each one.
Hint: Use the function
typeof()to examine what is returned in each case.Solution to Challenge 3
cats[1]coat 1 calico 2 black 3 tabbyWe can think of a data frame as a list of vectors. The single brace
[1]returns the first slice of the list, as another list. In this case it is the first column of the data frame.cats[[1]][1] calico black tabby Levels: black calico tabbyThe double brace
[[1]]returns the contents of the list item. In this case it is the contents of the first column, a vector of type factor.cats$coat[1] calico black tabby Levels: black calico tabbyThis example uses the
$character to address items by name. coat is the first column of the data frame, again a vector of type factor.cats["coat"]coat 1 calico 2 black 3 tabbyHere we are using a single brace
["coat"]replacing the index number with the column name. Like example 1, the returned object is a list.cats[1, 1][1] calico Levels: black calico tabbyThis example uses a single brace, but this time we provide row and column coordinates. The returned object is the value in row 1, column 1. The object is an integer but because it is part of a vector of type factor, R displays the label “calico” associated with the integer value.
cats[, 1][1] calico black tabby Levels: black calico tabbyLike the previous example we use single braces and provide row and column coordinates. The row coordinate is not specified, R interprets this missing value as all the elements in this column vector.
cats[1, ]coat weight likes_string 1 calico 2.1 1Again we use the single brace with row and column coordinates. The column coordinate is not specified. The return value is a list containing all the values in the first row.
Matrices
Last but not least is the matrix. We can declare a matrix full of zeros:
matrix_example <- matrix(0, ncol=6, nrow=3)
matrix_example
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 0 0 0 0 0 0
[2,] 0 0 0 0 0 0
[3,] 0 0 0 0 0 0
And similar to other data structures, we can ask things about our matrix:
class(matrix_example)
[1] "matrix" "array"
typeof(matrix_example)
[1] "double"
str(matrix_example)
num [1:3, 1:6] 0 0 0 0 0 0 0 0 0 0 ...
dim(matrix_example)
[1] 3 6
nrow(matrix_example)
[1] 3
ncol(matrix_example)
[1] 6
Challenge 4
What do you think will be the result of
length(matrix_example)? Try it. Were you right? Why / why not?Solution to Challenge 4
What do you think will be the result of
length(matrix_example)?matrix_example <- matrix(0, ncol=6, nrow=3) length(matrix_example)[1] 18Because a matrix is a vector with added dimension attributes,
lengthgives you the total number of elements in the matrix.
Challenge 5
Make another matrix, this time containing the numbers 1:50, with 5 columns and 10 rows. Did the
matrixfunction fill your matrix by column, or by row, as its default behaviour? See if you can figure out how to change this. (hint: read the documentation formatrix!)Solution to Challenge 5
Make another matrix, this time containing the numbers 1:50, with 5 columns and 10 rows. Did the
matrixfunction fill your matrix by column, or by row, as its default behaviour? See if you can figure out how to change this. (hint: read the documentation formatrix!)x <- matrix(1:50, ncol=5, nrow=10) x <- matrix(1:50, ncol=5, nrow=10, byrow = TRUE) # to fill by row
Challenge 6
Create a list of length two containing a character vector for each of the sections in this part of the workshop:
- Data types
- Data structures
Populate each character vector with the names of the data types and data structures we’ve seen so far.
Solution to Challenge 6
dataTypes <- c('double', 'complex', 'integer', 'character', 'logical') dataStructures <- c('data.frame', 'vector', 'factor', 'list', 'matrix') answer <- list(dataTypes, dataStructures)Note: it’s nice to make a list in big writing on the board or taped to the wall listing all of these types and structures - leave it up for the rest of the workshop to remind people of the importance of these basics.
Challenge 7
Consider the R output of the matrix below:
[,1] [,2] [1,] 4 1 [2,] 9 5 [3,] 10 7What was the correct command used to write this matrix? Examine each command and try to figure out the correct one before typing them. Think about what matrices the other commands will produce.
matrix(c(4, 1, 9, 5, 10, 7), nrow = 3)matrix(c(4, 9, 10, 1, 5, 7), ncol = 2, byrow = TRUE)matrix(c(4, 9, 10, 1, 5, 7), nrow = 2)matrix(c(4, 1, 9, 5, 10, 7), ncol = 2, byrow = TRUE)Solution to Challenge 7
Consider the R output of the matrix below:
[,1] [,2] [1,] 4 1 [2,] 9 5 [3,] 10 7What was the correct command used to write this matrix? Examine each command and try to figure out the correct one before typing them. Think about what matrices the other commands will produce.
matrix(c(4, 1, 9, 5, 10, 7), ncol = 2, byrow = TRUE)
Key Points
Use
read.csvto read tabular data in R.The basic data types in R are double, integer, complex, logical, and character.
Use factors to represent categories in R.
Exploring Data Frames
Overview
Teaching: 20 min
Exercises: 10 minQuestions
How can I manipulate a data frame?
Objectives
Add and remove rows or columns.
Remove rows with
NAvalues.Append two data frames.
Understand what a
factoris.Convert a
factorto acharactervector and vice versa.Display basic properties of data frames including size and class of the columns, names, and first few rows.
At this point, you’ve seen it all: in the last lesson, we toured all the basic data types and data structures in R. Everything you do will be a manipulation of those tools. But most of the time, the star of the show is the data frame—the table that we created by loading information from a csv file. In this lesson, we’ll learn a few more things about working with data frames.
Adding columns and rows in data frames
We already learned that the columns of a data frame are vectors, so that our data are consistent in type throughout the columns. As such, if we want to add a new column, we can start by making a new vector:
age <- c(2, 3, 5)
cats
coat weight likes_string
1 calico 2.1 1
2 black 5.0 0
3 tabby 3.2 1
We can then add this as a column via:
cbind(cats, age)
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
Note that if we tried to add a vector of ages with a different number of entries than the number of rows in the data frame, it would fail:
age <- c(2, 3, 5, 12)
cbind(cats, age)
Error in data.frame(..., check.names = FALSE): arguments imply differing number of rows: 3, 4
age <- c(2, 3)
cbind(cats, age)
Error in data.frame(..., check.names = FALSE): arguments imply differing number of rows: 3, 2
Why didn’t this work? Of course, R wants to see one element in our new column for every row in the table:
nrow(cats)
[1] 3
length(age)
[1] 2
So for it to work we need to have nrow(cats) = length(age). Let’s overwrite the content of cats with our new data frame.
age <- c(2, 3, 5)
cats <- cbind(cats, age)
Now how about adding rows? We already know that the rows of a data frame are lists:
newRow <- list("tortoiseshell", 3.3, TRUE, 9)
cats <- rbind(cats, newRow)
Warning in `[<-.factor`(`*tmp*`, ri, value = "tortoiseshell"): invalid factor
level, NA generated
Looks like our attempt to use the rbind() function returns a warning. Recall that, unlike errors, warnings do not necessarily stop a function from performing its intended action. You can confirm this by taking a look at the cats data frame.
cats
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
4 <NA> 3.3 1 9
Notice that not only did we successfully add a new row, but there is NA in the column coats where we expected “tortoiseshell” to be. Why did this happen?
Factors
For an object containing the data type factor, each different value represents what is called a level. In our case, the factor “coat” has 3 levels: “black”, “calico”, and “tabby”. R will only accept values that match one of the levels. If you add a new value, it will become NA.
The warning is telling us that we unsuccessfully added “tortoiseshell” to our coat factor, but 3.3 (a numeric), TRUE (a logical), and 9 (a numeric) were successfully added to weight, likes_string, and age, respectively, since those variables are not factors. To successfully add a cat with a “tortoiseshell” coat, add “tortoiseshell” as a possible level of the factor:
levels(cats$coat)
[1] "black" "calico" "tabby"
levels(cats$coat) <- c(levels(cats$coat), "tortoiseshell")
cats <- rbind(cats, list("tortoiseshell", 3.3, TRUE, 9))
Alternatively, we can change a factor into a character vector; we lose the handy categories of the factor, but we can subsequently add any word we want to the column without babysitting the factor levels:
str(cats)
'data.frame': 5 obs. of 4 variables:
$ coat : Factor w/ 4 levels "black","calico",..: 2 1 3 NA 4
$ weight : num 2.1 5 3.2 3.3 3.3
$ likes_string: int 1 0 1 1 1
$ age : num 2 3 5 9 9
cats$coat <- as.character(cats$coat)
str(cats)
'data.frame': 5 obs. of 4 variables:
$ coat : chr "calico" "black" "tabby" NA ...
$ weight : num 2.1 5 3.2 3.3 3.3
$ likes_string: int 1 0 1 1 1
$ age : num 2 3 5 9 9
Challenge 1
Let’s imagine that 1 cat year is equivalent to 7 human years.
- Create a vector called
human_ageby multiplyingcats$ageby 7.- Convert
human_ageto a factor.- Convert
human_ageback to a numeric vector using theas.numeric()function. Now divide it by 7 to get the original ages back. Explain what happened.Solution to Challenge 1
human_age <- cats$age * 7human_age <- factor(human_age).as.factor(human_age)works just as well.as.numeric(human_age)yields1 2 3 4 4because factors are stored as integers (here, 1:4), each of which is associated with a label (here, 28, 35, 56, and 63). Converting the factor to a numeric vector gives us the underlying integers, not the labels. If we want the original numbers, we need to converthuman_ageto a character vector (usingas.character(human_age)) and then to a numeric vector (why does this work?). This comes up in real life when we accidentally include a character somewhere in a column of a .csv file supposed to only contain numbers, and forget to setstringsAsFactors=FALSEwhen we read in the data.
Removing rows
We now know how to add rows and columns to our data frame in R—but in our first attempt to add a “tortoiseshell” cat to the data frame we have accidentally added a garbage row:
cats
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
4 <NA> 3.3 1 9
5 tortoiseshell 3.3 1 9
We can ask for a data frame minus this offending row:
cats[-4, ]
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
5 tortoiseshell 3.3 1 9
Notice the comma with nothing after it to indicate that we want to drop the entire fourth row.
Note: we could also remove both new rows at once by putting the row numbers
inside of a vector: cats[c(-4,-5), ]
Alternatively, we can drop all rows with NA values:
na.omit(cats)
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
5 tortoiseshell 3.3 1 9
Let’s reassign the output to cats, so that our changes will be permanent:
cats <- na.omit(cats)
Removing columns
We can also remove columns in our data frame. What if we want to remove the column “age”. We can remove it in two ways, by variable number or by index.
cats[,-4]
coat weight likes_string
1 calico 2.1 1
2 black 5.0 0
3 tabby 3.2 1
5 tortoiseshell 3.3 1
Notice the comma with nothing before it, indicating we want to keep all of the rows.
Alternatively, we can drop the column by using the index name and the %in% operator. The %in% operator goes through each element of its left argument, in this case the names of cats, and asks, “Does this element occur in the second argument?”
drop <- names(cats) %in% c("age")
cats[,!drop]
coat weight likes_string
1 calico 2.1 1
2 black 5.0 0
3 tabby 3.2 1
5 tortoiseshell 3.3 1
We will cover subsetting with logical operators like %in% in more detail in the next episode. See the section Subsetting through other logical operations
Appending to a data frame
The key to remember when adding data to a data frame is that columns are
vectors and rows are lists. We can also glue two data frames
together with rbind:
cats <- rbind(cats, cats)
cats
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
5 tortoiseshell 3.3 1 9
11 calico 2.1 1 2
21 black 5.0 0 3
31 tabby 3.2 1 5
51 tortoiseshell 3.3 1 9
But now the row names are unnecessarily complicated. We can remove the rownames, and R will automatically re-name them sequentially:
rownames(cats) <- NULL
cats
coat weight likes_string age
1 calico 2.1 1 2
2 black 5.0 0 3
3 tabby 3.2 1 5
4 tortoiseshell 3.3 1 9
5 calico 2.1 1 2
6 black 5.0 0 3
7 tabby 3.2 1 5
8 tortoiseshell 3.3 1 9
Challenge 2
You can create a new data frame right from within R with the following syntax:
df <- data.frame(id = c("a", "b", "c"), x = 1:3, y = c(TRUE, TRUE, FALSE), stringsAsFactors = FALSE)Make a data frame that holds the following information for yourself:
- first name
- last name
- lucky number
Then use
rbindto add an entry for the people sitting beside you. Finally, usecbindto add a column with each person’s answer to the question, “Is it time for coffee break?”Solution to Challenge 2
df <- data.frame(first = c("Grace"), last = c("Hopper"), lucky_number = c(0), stringsAsFactors = FALSE) df <- rbind(df, list("Marie", "Curie", 238) ) df <- cbind(df, coffeetime = c(TRUE,TRUE))
Realistic example
So far, you have seen the basics of manipulating data frames with our cat data;
now let’s use those skills to digest a more realistic dataset. Let’s read in the
gapminder dataset that we downloaded previously:
gapminder <- read.csv("data/gapminder_data.csv", stringsAsFactors = TRUE)
Miscellaneous Tips
Another type of file you might encounter are tab-separated value files (.tsv). To specify a tab as a separator, use
"\\t"orread.delim().Files can also be downloaded directly from the Internet into a local folder of your choice onto your computer using the
download.filefunction. Theread.csvfunction can then be executed to read the downloaded file from the download location, for example,download.file("https://raw.githubusercontent.com/swcarpentry/r-novice-gapminder/gh-pages/_episodes_rmd/data/gapminder_data.csv", destfile = "data/gapminder_data.csv") gapminder <- read.csv("data/gapminder_data.csv", stringsAsFactors = TRUE)
- Alternatively, you can also read in files directly into R from the Internet by replacing the file paths with a web address in
read.csv. One should note that in doing this no local copy of the csv file is first saved onto your computer. For example,gapminder <- read.csv("https://raw.githubusercontent.com/swcarpentry/r-novice-gapminder/gh-pages/_episodes_rmd/data/gapminder_data.csv", stringsAsFactors = TRUE)
- You can read directly from excel spreadsheets without converting them to plain text first by using the readxl package.
Let’s investigate gapminder a bit; the first thing we should always do is check
out what the data looks like with str:
str(gapminder)
'data.frame': 1704 obs. of 6 variables:
$ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
$ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ pop : num 8425333 9240934 10267083 11537966 13079460 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
$ lifeExp : num 28.8 30.3 32 34 36.1 ...
$ gdpPercap: num 779 821 853 836 740 ...
An additional method for examining the structure of gapminder is to use the summary function. This function can be used on various objects in R. For data frames, summary yields a numeric, tabular, or descriptive summary of each column. Factor columns are summarized by the number of items in each level, numeric or integer columns by the descriptive statistics (quartiles and mean), and character columns by its length, class, and mode.
summary(gapminder$country)
Afghanistan Albania Algeria
12 12 12
Angola Argentina Australia
12 12 12
Austria Bahrain Bangladesh
12 12 12
Belgium Benin Bolivia
12 12 12
Bosnia and Herzegovina Botswana Brazil
12 12 12
Bulgaria Burkina Faso Burundi
12 12 12
Cambodia Cameroon Canada
12 12 12
Central African Republic Chad Chile
12 12 12
China Colombia Comoros
12 12 12
Congo Dem. Rep. Congo Rep. Costa Rica
12 12 12
Cote d'Ivoire Croatia Cuba
12 12 12
Czech Republic Denmark Djibouti
12 12 12
Dominican Republic Ecuador Egypt
12 12 12
El Salvador Equatorial Guinea Eritrea
12 12 12
Ethiopia Finland France
12 12 12
Gabon Gambia Germany
12 12 12
Ghana Greece Guatemala
12 12 12
Guinea Guinea-Bissau Haiti
12 12 12
Honduras Hong Kong China Hungary
12 12 12
Iceland India Indonesia
12 12 12
Iran Iraq Ireland
12 12 12
Israel Italy Jamaica
12 12 12
Japan Jordan Kenya
12 12 12
Korea Dem. Rep. Korea Rep. Kuwait
12 12 12
Lebanon Lesotho Liberia
12 12 12
Libya Madagascar Malawi
12 12 12
Malaysia Mali Mauritania
12 12 12
Mauritius Mexico Mongolia
12 12 12
Montenegro Morocco Mozambique
12 12 12
Myanmar Namibia Nepal
12 12 12
Netherlands New Zealand Nicaragua
12 12 12
Niger Nigeria Norway
12 12 12
Oman Pakistan Panama
12 12 12
(Other)
516
Along with the str and summary functions, we can examine individual columns of the data frame with our typeof function:
typeof(gapminder$year)
[1] "integer"
typeof(gapminder$country)
[1] "integer"
str(gapminder$country)
Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
We can also interrogate the data frame for information about its dimensions;
remembering that str(gapminder) said there were 1704 observations of 6
variables in gapminder, what do you think the following will produce, and why?
length(gapminder)
[1] 6
A fair guess would have been to say that the length of a data frame would be the number of rows it has (1704), but this is not the case; remember, a data frame is a list of vectors and factors:
typeof(gapminder)
[1] "list"
When length gave us 6, it’s because gapminder is built out of a list of 6
columns. To get the number of rows and columns in our dataset, try:
nrow(gapminder)
[1] 1704
ncol(gapminder)
[1] 6
Or, both at once:
dim(gapminder)
[1] 1704 6
We’ll also likely want to know what the titles of all the columns are, so we can ask for them later:
colnames(gapminder)
[1] "country" "year" "pop" "continent" "lifeExp" "gdpPercap"
At this stage, it’s important to ask ourselves if the structure R is reporting matches our intuition or expectations; do the basic data types reported for each column make sense? If not, we need to sort any problems out now before they turn into bad surprises down the road, using what we’ve learned about how R interprets data, and the importance of strict consistency in how we record our data.
Once we’re happy that the data types and structures seem reasonable, it’s time to start digging into our data proper. Check out the first few lines:
head(gapminder)
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
4 Afghanistan 1967 11537966 Asia 34.020 836.1971
5 Afghanistan 1972 13079460 Asia 36.088 739.9811
6 Afghanistan 1977 14880372 Asia 38.438 786.1134
Challenge 3
It’s good practice to also check the last few lines of your data and some in the middle. How would you do this?
Searching for ones specifically in the middle isn’t too hard, but we could ask for a few lines at random. How would you code this?
Solution to Challenge 3
To check the last few lines it’s relatively simple as R already has a function for this:
tail(gapminder) tail(gapminder, n = 15)What about a few arbitrary rows just in case something is odd in the middle?
Tip: There are several ways to achieve this.
The solution here presents one form of using nested functions, i.e. a function passed as an argument to another function. This might sound like a new concept, but you are already using it! Remember my_dataframe[rows, cols] will print to screen your data frame with the number of rows and columns you asked for (although you might have asked for a range or named columns for example). How would you get the last row if you don’t know how many rows your data frame has? R has a function for this. What about getting a (pseudorandom) sample? R also has a function for this.
gapminder[sample(nrow(gapminder), 5), ]
To make sure our analysis is reproducible, we should put the code into a script file so we can come back to it later.
Challenge 4
Go to file -> new file -> R script, and write an R script to load in the gapminder dataset. Put it in the
scripts/directory and add it to version control.Run the script using the
sourcefunction, using the file path as its argument (or by pressing the “source” button in RStudio).Solution to Challenge 4
The
sourcefunction can be used to use a script within a script. Assume you would like to load the same type of file over and over again and therefore you need to specify the arguments to fit the needs of your file. Instead of writing the necessary argument again and again you could just write it once and save it as a script. Then, you can usesource("Your_Script_containing_the_load_function")in a new script to use the function of that script without writing everything again. Check out?sourceto find out more.download.file("https://raw.githubusercontent.com/swcarpentry/r-novice-gapminder/gh-pages/_episodes_rmd/data/gapminder_data.csv", destfile = "data/gapminder_data.csv") gapminder <- read.csv(file = "data/gapminder_data.csv", stringsAsFactors = TRUE)To run the script and load the data into the
gapmindervariable:source(file = "scripts/load-gapminder.R")
Challenge 5
Read the output of
str(gapminder)again; this time, use what you’ve learned about factors, lists and vectors, as well as the output of functions likecolnamesanddimto explain what everything thatstrprints out for gapminder means. If there are any parts you can’t interpret, discuss with your neighbors!Solution to Challenge 5
The object
gapminderis a data frame with columns
countryandcontinentare factors.yearis an integer vector.pop,lifeExp, andgdpPercapare numeric vectors.
Key Points
Use
cbind()to add a new column to a data frame.Use
rbind()to add a new row to a data frame.Remove rows from a data frame.
Use
na.omit()to remove rows from a data frame withNAvalues.Use
levels()andas.character()to explore and manipulate factors.Use
str(),summary(),nrow(),ncol(),dim(),colnames(),rownames(),head(), andtypeof()to understand the structure of a data frame.Read in a csv file using
read.csv().Understand what
length()of a data frame represents.
Subsetting Data
Overview
Teaching: 35 min
Exercises: 15 minQuestions
How can I work with subsets of data in R?
Objectives
To be able to subset vectors, factors, matrices, lists, and data frames
To be able to extract individual and multiple elements: by index, by name, using comparison operations
To be able to skip and remove elements from various data structures.
R has many powerful subset operators. Mastering them will allow you to easily perform complex operations on any kind of dataset.
There are six different ways we can subset any kind of object, and three different subsetting operators for the different data structures.
Let’s start with the workhorse of R: a simple numeric vector.
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
x
a b c d e
5.4 6.2 7.1 4.8 7.5
Atomic vectors
In R, simple vectors containing character strings, numbers, or logical values are called atomic vectors because they can’t be further simplified.
So now that we’ve created a dummy vector to play with, how do we get at its contents?
Accessing elements using their indices
To extract elements of a vector we can give their corresponding index, starting from one:
x[1]
a
5.4
x[4]
d
4.8
It may look different, but the square brackets operator is a function. For vectors (and matrices), it means “get me the nth element”.
We can ask for multiple elements at once:
x[c(1, 3)]
a c
5.4 7.1
Or slices of the vector:
x[1:4]
a b c d
5.4 6.2 7.1 4.8
the : operator creates a sequence of numbers from the left element to the right.
1:4
[1] 1 2 3 4
c(1, 2, 3, 4)
[1] 1 2 3 4
We can ask for the same element multiple times:
x[c(1,1,3)]
a a c
5.4 5.4 7.1
If we ask for an index beyond the length of the vector, R will return a missing value:
x[6]
<NA>
NA
This is a vector of length one containing an NA, whose name is also NA.
If we ask for the 0th element, we get an empty vector:
x[0]
named numeric(0)
Vector numbering in R starts at 1
In many programming languages (C and Python, for example), the first element of a vector has an index of 0. In R, the first element is 1.
Skipping and removing elements
If we use a negative number as the index of a vector, R will return every element except for the one specified:
x[-2]
a c d e
5.4 7.1 4.8 7.5
We can skip multiple elements:
x[c(-1, -5)] # or x[-c(1,5)]
b c d
6.2 7.1 4.8
Tip: Order of operations
A common trip up for novices occurs when trying to skip slices of a vector. It’s natural to try to negate a sequence like so:
x[-1:3]This gives a somewhat cryptic error:
Error in x[-1:3]: only 0's may be mixed with negative subscriptsBut remember the order of operations.
:is really a function. It takes its first argument as -1, and its second as 3, so generates the sequence of numbers:c(-1, 0, 1, 2, 3).The correct solution is to wrap that function call in brackets, so that the
-operator applies to the result:x[-(1:3)]d e 4.8 7.5
To remove elements from a vector, we need to assign the result back into the variable:
x <- x[-4]
x
a b c e
5.4 6.2 7.1 7.5
Challenge 1
Given the following code:
x <- c(5.4, 6.2, 7.1, 4.8, 7.5) names(x) <- c('a', 'b', 'c', 'd', 'e') print(x)a b c d e 5.4 6.2 7.1 4.8 7.5Come up with at least 2 different commands that will produce the following output:
b c d 6.2 7.1 4.8After you find 2 different commands, compare notes with your neighbour. Did you have different strategies?
Solution to challenge 1
x[2:4]b c d 6.2 7.1 4.8x[-c(1,5)]b c d 6.2 7.1 4.8x[c(2,3,4)]b c d 6.2 7.1 4.8
Subsetting by name
We can extract elements by using their name, instead of extracting by index:
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # we can name a vector 'on the fly'
x[c("a", "c")]
a c
5.4 7.1
This is usually a much more reliable way to subset objects: the position of various elements can often change when chaining together subsetting operations, but the names will always remain the same!
Subsetting through other logical operations
We can also use any logical vector to subset:
x[c(FALSE, FALSE, TRUE, FALSE, TRUE)]
c e
7.1 7.5
Since comparison operators (e.g. >, <, ==) evaluate to logical vectors, we can also
use them to succinctly subset vectors: the following statement gives
the same result as the previous one.
x[x > 7]
c e
7.1 7.5
Breaking it down, this statement first evaluates x>7, generating
a logical vector c(FALSE, FALSE, TRUE, FALSE, TRUE), and then
selects the elements of x corresponding to the TRUE values.
We can use == to mimic the previous method of indexing by name
(remember you have to use == rather than = for comparisons):
x[names(x) == "a"]
a
5.4
Tip: Combining logical conditions
We often want to combine multiple logical criteria. For example, we might want to find all the countries that are located in Asia or Europe and have life expectancies within a certain range. Several operations for combining logical vectors exist in R:
&, the “logical AND” operator: returnsTRUEif both the left and right areTRUE.|, the “logical OR” operator: returnsTRUE, if either the left or right (or both) areTRUE.You may sometimes see
&&and||instead of&and|. These two-character operators only look at the first element of each vector and ignore the remaining elements. In general you should not use the two-character operators in data analysis; save them for programming, i.e. deciding whether to execute a statement.
!, the “logical NOT” operator: convertsTRUEtoFALSEandFALSEtoTRUE. It can negate a single logical condition (eg!TRUEbecomesFALSE), or a whole vector of conditions(eg!c(TRUE, FALSE)becomesc(FALSE, TRUE)).Additionally, you can compare the elements within a single vector using the
allfunction (which returnsTRUEif every element of the vector isTRUE) and theanyfunction (which returnsTRUEif one or more elements of the vector areTRUE).
Challenge 2
Given the following code:
x <- c(5.4, 6.2, 7.1, 4.8, 7.5) names(x) <- c('a', 'b', 'c', 'd', 'e') print(x)a b c d e 5.4 6.2 7.1 4.8 7.5Write a subsetting command to return the values in x that are greater than 4 and less than 7.
Solution to challenge 2
x_subset <- x[x<7 & x>4] print(x_subset)a b d 5.4 6.2 4.8
Tip: Non-unique names
You should be aware that it is possible for multiple elements in a vector to have the same name. (For a data frame, columns can have the same name — although R tries to avoid this — but row names must be unique.) Consider these examples:
x <- 1:3 x[1] 1 2 3names(x) <- c('a', 'a', 'a') xa a a 1 2 3x['a'] # only returns first valuea 1x[names(x) == 'a'] # returns all three valuesa a a 1 2 3
Tip: Getting help for operators
Remember you can search for help on operators by wrapping them in quotes:
help("%in%")or?"%in%".
Skipping named elements
Skipping or removing named elements is a little harder. If we try to skip one named element by negating the string, R complains (slightly obscurely) that it doesn’t know how to take the negative of a string:
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # we start again by naming a vector 'on the fly'
x[-"a"]
Error in -"a": invalid argument to unary operator
However, we can use the != (not-equals) operator to construct a logical vector that will do what we want:
x[names(x) != "a"]
b c d e
6.2 7.1 4.8 7.5
Skipping multiple named indices is a little bit harder still. Suppose we want to drop the "a" and "c" elements, so we try this:
x[names(x)!=c("a","c")]
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object length
b c d e
6.2 7.1 4.8 7.5
R did something, but it gave us a warning that we ought to pay attention to - and it apparently gave us the wrong answer (the "c" element is still included in the vector)!
So what does != actually do in this case? That’s an excellent question.
Recycling
Let’s take a look at the comparison component of this code:
names(x) != c("a", "c")
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object length
[1] FALSE TRUE TRUE TRUE TRUE
Why does R give TRUE as the third element of this vector, when names(x)[3] != "c" is obviously false?
When you use !=, R tries to compare each element
of the left argument with the corresponding element of its right
argument. What happens when you compare vectors of different lengths?
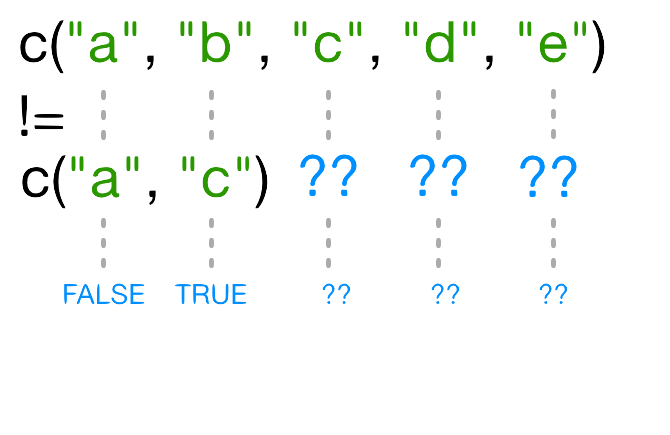
When one vector is shorter than the other, it gets recycled:
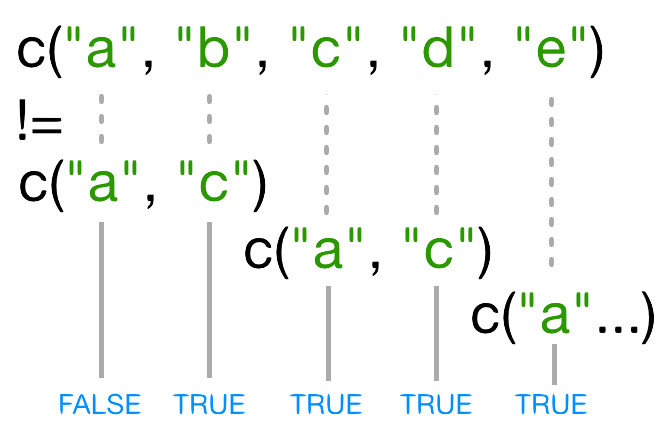
In this case R repeats c("a", "c") as many times as necessary to match names(x), i.e. we get c("a","c","a","c","a"). Since the recycled "a"
doesn’t match the third element of names(x), the value of != is TRUE.
Because in this case the longer vector length (5) isn’t a multiple of the shorter vector length (2), R printed a warning message. If we had been unlucky and names(x) had contained six elements, R would silently have done the wrong thing (i.e., not what we intended it to do). This recycling rule can can introduce hard-to-find and subtle bugs!
The way to get R to do what we really want (match each element of the left argument with all of the elements of the right argument) it to use the %in% operator. The %in% operator goes through each element of its left argument, in this case the names of x, and asks, “Does this element occur in the second argument?”. Here, since we want to exclude values, we also need a ! operator to change “in” to “not in”:
x[! names(x) %in% c("a","c") ]
b d e
6.2 4.8 7.5
Challenge 3
Selecting elements of a vector that match any of a list of components is a very common data analysis task. For example, the gapminder data set contains
countryandcontinentvariables, but no information between these two scales. Suppose we want to pull out information from southeast Asia: how do we set up an operation to produce a logical vector that isTRUEfor all of the countries in southeast Asia andFALSEotherwise?Suppose you have these data:
seAsia <- c("Myanmar","Thailand","Cambodia","Vietnam","Laos") ## read in the gapminder data that we downloaded in episode 2 gapminder <- read.csv("data/gapminder_data.csv", header=TRUE) ## extract the `country` column from a data frame (we'll see this later); ## convert from a factor to a character; ## and get just the non-repeated elements countries <- unique(as.character(gapminder$country))There’s a wrong way (using only
==), which will give you a warning; a clunky way (using the logical operators==and|); and an elegant way (using%in%). See whether you can come up with all three and explain how they (don’t) work.Solution to challenge 3
- The wrong way to do this problem is
countries==seAsia. This gives a warning ("In countries == seAsia : longer object length is not a multiple of shorter object length") and the wrong answer (a vector of allFALSEvalues), because none of the recycled values ofseAsiahappen to line up correctly with matching values incountry.- The clunky (but technically correct) way to do this problem is
(countries=="Myanmar" | countries=="Thailand" | countries=="Cambodia" | countries == "Vietnam" | countries=="Laos")(or
countries==seAsia[1] | countries==seAsia[2] | ...). This gives the correct values, but hopefully you can see how awkward it is (what if we wanted to select countries from a much longer list?).
- The best way to do this problem is
countries %in% seAsia, which is both correct and easy to type (and read).
Handling special values
At some point you will encounter functions in R that cannot handle missing, infinite, or undefined data.
There are a number of special functions you can use to filter out this data:
is.nawill return all positions in a vector, matrix, or data.frame containingNA(orNaN)- likewise,
is.nan, andis.infinitewill do the same forNaNandInf. is.finitewill return all positions in a vector, matrix, or data.frame that do not containNA,NaNorInf.na.omitwill filter out all missing values from a vector
Factor subsetting
Now that we’ve explored the different ways to subset vectors, how do we subset the other data structures?
Factor subsetting works the same way as vector subsetting.
f <- factor(c("a", "a", "b", "c", "c", "d"))
f[f == "a"]
[1] a a
Levels: a b c d
f[f %in% c("b", "c")]
[1] b c c
Levels: a b c d
f[1:3]
[1] a a b
Levels: a b c d
Skipping elements will not remove the level even if no more of that category exists in the factor:
f[-3]
[1] a a c c d
Levels: a b c d
Matrix subsetting
Matrices are also subsetted using the [ function. In this case
it takes two arguments: the first applying to the rows, the second
to its columns:
set.seed(1)
m <- matrix(rnorm(6*4), ncol=4, nrow=6)
m[3:4, c(3,1)]
[,1] [,2]
[1,] 1.12493092 -0.8356286
[2,] -0.04493361 1.5952808
You can leave the first or second arguments blank to retrieve all the rows or columns respectively:
m[, c(3,4)]
[,1] [,2]
[1,] -0.62124058 0.82122120
[2,] -2.21469989 0.59390132
[3,] 1.12493092 0.91897737
[4,] -0.04493361 0.78213630
[5,] -0.01619026 0.07456498
[6,] 0.94383621 -1.98935170
If we only access one row or column, R will automatically convert the result to a vector:
m[3,]
[1] -0.8356286 0.5757814 1.1249309 0.9189774
If you want to keep the output as a matrix, you need to specify a third argument;
drop = FALSE:
m[3, , drop=FALSE]
[,1] [,2] [,3] [,4]
[1,] -0.8356286 0.5757814 1.124931 0.9189774
Unlike vectors, if we try to access a row or column outside of the matrix, R will throw an error:
m[, c(3,6)]
Error in m[, c(3, 6)]: subscript out of bounds
Tip: Higher dimensional arrays
when dealing with multi-dimensional arrays, each argument to
[corresponds to a dimension. For example, a 3D array, the first three arguments correspond to the rows, columns, and depth dimension.
Because matrices are vectors, we can also subset using only one argument:
m[5]
[1] 0.3295078
This usually isn’t useful, and often confusing to read. However it is useful to note that matrices are laid out in column-major format by default. That is the elements of the vector are arranged column-wise:
matrix(1:6, nrow=2, ncol=3)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
If you wish to populate the matrix by row, use byrow=TRUE:
matrix(1:6, nrow=2, ncol=3, byrow=TRUE)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
Matrices can also be subsetted using their rownames and column names instead of their row and column indices.
Challenge 4
Given the following code:
m <- matrix(1:18, nrow=3, ncol=6) print(m)[,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 4 7 10 13 16 [2,] 2 5 8 11 14 17 [3,] 3 6 9 12 15 18
- Which of the following commands will extract the values 11 and 14?
A.
m[2,4,2,5]B.
m[2:5]C.
m[4:5,2]D.
m[2,c(4,5)]Solution to challenge 4
D
List subsetting
Now we’ll introduce some new subsetting operators. There are three functions
used to subset lists. We’ve already seen these when learning about atomic vectors and matrices: [, [[, and $.
Using [ will always return a list. If you want to subset a list, but not
extract an element, then you will likely use [.
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
xlist[1]
$a
[1] "Software Carpentry"
This returns a list with one element.
We can subset elements of a list exactly the same way as atomic
vectors using [. Comparison operations however won’t work as
they’re not recursive, they will try to condition on the data structures
in each element of the list, not the individual elements within those
data structures.
xlist[1:2]
$a
[1] "Software Carpentry"
$b
[1] 1 2 3 4 5 6 7 8 9 10
To extract individual elements of a list, you need to use the double-square
bracket function: [[.
xlist[[1]]
[1] "Software Carpentry"
Notice that now the result is a vector, not a list.
You can’t extract more than one element at once:
xlist[[1:2]]
Error in xlist[[1:2]]: subscript out of bounds
Nor use it to skip elements:
xlist[[-1]]
Error in xlist[[-1]]: invalid negative subscript in get1index <real>
But you can use names to both subset and extract elements:
xlist[["a"]]
[1] "Software Carpentry"
The $ function is a shorthand way for extracting elements by name:
xlist$data
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
Challenge 5
Given the following list:
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))Using your knowledge of both list and vector subsetting, extract the number 2 from xlist. Hint: the number 2 is contained within the “b” item in the list.
Solution to challenge 5
xlist$b[2][1] 2xlist[[2]][2][1] 2xlist[["b"]][2][1] 2
Challenge 6
Given a linear model:
mod <- aov(pop ~ lifeExp, data=gapminder)Extract the residual degrees of freedom (hint:
attributes()will help you)Solution to challenge 6
attributes(mod) ## `df.residual` is one of the names of `mod`mod$df.residual
Data frames
Remember the data frames are lists underneath the hood, so similar rules apply. However they are also two dimensional objects:
[ with one argument will act the same way as for lists, where each list
element corresponds to a column. The resulting object will be a data frame:
head(gapminder[3])
pop
1 8425333
2 9240934
3 10267083
4 11537966
5 13079460
6 14880372
Similarly, [[ will act to extract a single column:
head(gapminder[["lifeExp"]])
[1] 28.801 30.332 31.997 34.020 36.088 38.438
And $ provides a convenient shorthand to extract columns by name:
head(gapminder$year)
[1] 1952 1957 1962 1967 1972 1977
With two arguments, [ behaves the same way as for matrices:
gapminder[1:3,]
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
If we subset a single row, the result will be a data frame (because the elements are mixed types):
gapminder[3,]
country year pop continent lifeExp gdpPercap
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
But for a single column the result will be a vector (this can
be changed with the third argument, drop = FALSE).
Challenge 7
Fix each of the following common data frame subsetting errors:
Extract observations collected for the year 1957
gapminder[gapminder$year = 1957,]Extract all columns except 1 through to 4
gapminder[,-1:4]Extract the rows where the life expectancy is longer the 80 years
gapminder[gapminder$lifeExp > 80]Extract the first row, and the fourth and fifth columns (
continentandlifeExp).gapminder[1, 4, 5]Advanced: extract rows that contain information for the years 2002 and 2007
gapminder[gapminder$year == 2002 | 2007,]Solution to challenge 7
Fix each of the following common data frame subsetting errors:
Extract observations collected for the year 1957
# gapminder[gapminder$year = 1957,] gapminder[gapminder$year == 1957,]Extract all columns except 1 through to 4
# gapminder[,-1:4] gapminder[,-c(1:4)]Extract the rows where the life expectancy is longer than 80 years
# gapminder[gapminder$lifeExp > 80] gapminder[gapminder$lifeExp > 80,]Extract the first row, and the fourth and fifth columns (
continentandlifeExp).# gapminder[1, 4, 5] gapminder[1, c(4, 5)]Advanced: extract rows that contain information for the years 2002 and 2007
# gapminder[gapminder$year == 2002 | 2007,] gapminder[gapminder$year == 2002 | gapminder$year == 2007,] gapminder[gapminder$year %in% c(2002, 2007),]
Challenge 8
Why does
gapminder[1:20]return an error? How does it differ fromgapminder[1:20, ]?Create a new
data.framecalledgapminder_smallthat only contains rows 1 through 9 and 19 through 23. You can do this in one or two steps.Solution to challenge 8
gapminderis a data.frame so needs to be subsetted on two dimensions.gapminder[1:20, ]subsets the data to give the first 20 rows and all columns.gapminder_small <- gapminder[c(1:9, 19:23),]
Key Points
Indexing in R starts at 1, not 0.
Access individual values by location using
[].Access slices of data using
[low:high].Access arbitrary sets of data using
[c(...)].Use logical operations and logical vectors to access subsets of data.
Control Flow
Overview
Teaching: 45 min
Exercises: 20 minQuestions
How can I make data-dependent choices in R?
How can I repeat operations in R?
Objectives
Write conditional statements with
if...elsestatements andifelse().Write and understand
for()loops.
Often when we’re coding we want to control the flow of our actions. This can be done by setting actions to occur only if a condition or a set of conditions are met. Alternatively, we can also set an action to occur a particular number of times.
There are several ways you can control flow in R. For conditional statements, the most commonly used approaches are the constructs:
# if
if (condition is true) {
perform action
}
# if ... else
if (condition is true) {
perform action
} else { # that is, if the condition is false,
perform alternative action
}
Say, for example, that we want R to print a message if a variable x has a particular value:
x <- 8
if (x >= 10) {
print("x is greater than or equal to 10")
}
x
[1] 8
The print statement does not appear in the console because x is not greater than 10. To print a different message for numbers less than 10, we can add an else statement.
x <- 8
if (x >= 10) {
print("x is greater than or equal to 10")
} else {
print("x is less than 10")
}
[1] "x is less than 10"
You can also test multiple conditions by using else if.
x <- 8
if (x >= 10) {
print("x is greater than or equal to 10")
} else if (x > 5) {
print("x is greater than 5, but less than 10")
} else {
print("x is less than 5")
}
[1] "x is greater than 5, but less than 10"
Important: when R evaluates the condition inside if() statements, it is
looking for a logical element, i.e., TRUE or FALSE. This can cause some
headaches for beginners. For example:
x <- 4 == 3
if (x) {
"4 equals 3"
} else {
"4 does not equal 3"
}
[1] "4 does not equal 3"
As we can see, the not equal message was printed because the vector x is FALSE
x <- 4 == 3
x
[1] FALSE
Challenge 1
Use an
if()statement to print a suitable message reporting whether there are any records from 2002 in thegapminderdataset. Now do the same for 2012.Solution to Challenge 1
We will first see a solution to Challenge 1 which does not use the
any()function. We first obtain a logical vector describing which element ofgapminder$yearis equal to2002:gapminder[(gapminder$year == 2002),]Then, we count the number of rows of the data.frame
gapminderthat correspond to the 2002:rows2002_number <- nrow(gapminder[(gapminder$year == 2002),])The presence of any record for the year 2002 is equivalent to the request that
rows2002_numberis one or more:rows2002_number >= 1Putting all together, we obtain:
if(nrow(gapminder[(gapminder$year == 2002),]) >= 1){ print("Record(s) for the year 2002 found.") }All this can be done more quickly with
any(). The logical condition can be expressed as:if(any(gapminder$year == 2002)){ print("Record(s) for the year 2002 found.") }
Did anyone get a warning message like this?
Warning in if (gapminder$year == 2012) {: the condition has length > 1 and only
the first element will be used
The if() function only accepts singular (of length 1) inputs, and therefore
returns an error when you use it with a vector. The if() function will still
run, but will only evaluate the condition in the first element of the vector.
Therefore, to use the if() function, you need to make sure your input is
singular (of length 1).
Tip: Built in
ifelse()function
Raccepts bothif()andelse if()statements structured as outlined above, but also statements usingR’s built-inifelse()function. This function accepts both singular and vector inputs and is structured as follows:# ifelse function ifelse(condition is true, perform action, perform alternative action)where the first argument is the condition or a set of conditions to be met, the second argument is the statement that is evaluated when the condition is
TRUE, and the third statement is the statement that is evaluated when the condition isFALSE.y <- -3 ifelse(y < 0, "y is a negative number", "y is either positive or zero")[1] "y is a negative number"
Tip:
any()andall()The
any()function will returnTRUEif at least oneTRUEvalue is found within a vector, otherwise it will returnFALSE. This can be used in a similar way to the%in%operator. The functionall(), as the name suggests, will only returnTRUEif all values in the vector areTRUE.
Repeating operations
If you want to iterate over
a set of values, when the order of iteration is important, and perform the
same operation on each, a for() loop will do the job.
We saw for() loops in the shell lessons earlier. This is the most
flexible of looping operations, but therefore also the hardest to use
correctly. In general, the advice of many R users would be to learn about
for() loops, but to avoid using for() loops unless the order of iteration is
important: i.e. the calculation at each iteration depends on the results of
previous iterations. If the order of iteration is not important, then you
should learn about vectorized alternatives, such as the purrr package, as they
pay off in computational efficiency.
The basic structure of a for() loop is:
for (iterator in set of values) {
do a thing
}
For example:
for (i in 1:10) {
print(i)
}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10
The 1:10 bit creates a vector on the fly; you can iterate
over any other vector as well.
We can use a for() loop nested within another for() loop to iterate over two things at
once.
for (i in 1:5) {
for (j in c('a', 'b', 'c', 'd', 'e')) {
print(paste(i,j))
}
}
[1] "1 a"
[1] "1 b"
[1] "1 c"
[1] "1 d"
[1] "1 e"
[1] "2 a"
[1] "2 b"
[1] "2 c"
[1] "2 d"
[1] "2 e"
[1] "3 a"
[1] "3 b"
[1] "3 c"
[1] "3 d"
[1] "3 e"
[1] "4 a"
[1] "4 b"
[1] "4 c"
[1] "4 d"
[1] "4 e"
[1] "5 a"
[1] "5 b"
[1] "5 c"
[1] "5 d"
[1] "5 e"
We notice in the output that when the first index (i) is set to 1, the second
index (j) iterates through its full set of indices. Once the indices of j
have been iterated through, then i is incremented. This process continues
until the last index has been used for each for() loop.
Rather than printing the results, we could write the loop output to a new object.
output_vector <- c()
for (i in 1:5) {
for (j in c('a', 'b', 'c', 'd', 'e')) {
temp_output <- paste(i, j)
output_vector <- c(output_vector, temp_output)
}
}
output_vector
[1] "1 a" "1 b" "1 c" "1 d" "1 e" "2 a" "2 b" "2 c" "2 d" "2 e" "3 a" "3 b"
[13] "3 c" "3 d" "3 e" "4 a" "4 b" "4 c" "4 d" "4 e" "5 a" "5 b" "5 c" "5 d"
[25] "5 e"
This approach can be useful, but ‘growing your results’ (building the result object incrementally) is computationally inefficient, so avoid it when you are iterating through a lot of values.
Tip: don’t grow your results
One of the biggest things that trips up novices and experienced R users alike, is building a results object (vector, list, matrix, data frame) as your for loop progresses. Computers are very bad at handling this, so your calculations can very quickly slow to a crawl. It’s much better to define an empty results object before hand of appropriate dimensions, rather than initializing an empty object without dimensions. So if you know the end result will be stored in a matrix like above, create an empty matrix with 5 row and 5 columns, then at each iteration store the results in the appropriate location.
A better way is to define your (empty) output object before filling in the values. For this example, it looks more involved, but is still more efficient.
output_matrix <- matrix(nrow = 5, ncol = 5)
j_vector <- c('a', 'b', 'c', 'd', 'e')
for (i in 1:5) {
for (j in 1:5) {
temp_j_value <- j_vector[j]
temp_output <- paste(i, temp_j_value)
output_matrix[i, j] <- temp_output
}
}
output_vector2 <- as.vector(output_matrix)
output_vector2
[1] "1 a" "2 a" "3 a" "4 a" "5 a" "1 b" "2 b" "3 b" "4 b" "5 b" "1 c" "2 c"
[13] "3 c" "4 c" "5 c" "1 d" "2 d" "3 d" "4 d" "5 d" "1 e" "2 e" "3 e" "4 e"
[25] "5 e"
Tip: While loops
Sometimes you will find yourself needing to repeat an operation as long as a certain condition is met. You can do this with a
while()loop.while(this condition is true){ do a thing }R will interpret a condition being met as “TRUE”.
As an example, here’s a while loop that generates random numbers from a uniform distribution (the
runif()function) between 0 and 1 until it gets one that’s less than 0.1.z <- 1 while(z > 0.1){ z <- runif(1) cat(z, "\n") }
while()loops will not always be appropriate. You have to be particularly careful that you don’t end up stuck in an infinite loop because your condition is always met and hence the while statement never terminates.
Challenge 2
Compare the objects
output_vectorandoutput_vector2. Are they the same? If not, why not? How would you change the last block of code to makeoutput_vector2the same asoutput_vector?Solution to Challenge 2
We can check whether the two vectors are identical using the
all()function:all(output_vector == output_vector2)However, all the elements of
output_vectorcan be found inoutput_vector2:all(output_vector %in% output_vector2)and vice versa:
all(output_vector2 %in% output_vector)therefore, the element in
output_vectorandoutput_vector2are just sorted in a different order. This is becauseas.vector()outputs the elements of an input matrix going over its column. Taking a look atoutput_matrix, we can notice that we want its elements by rows. The solution is to transpose theoutput_matrix. We can do it either by calling the transpose functiont()or by inputting the elements in the right order. The first solution requires to change the originaloutput_vector2 <- as.vector(output_matrix)into
output_vector2 <- as.vector(t(output_matrix))The second solution requires to change
output_matrix[i, j] <- temp_outputinto
output_matrix[j, i] <- temp_output
Challenge 3
Write a script that loops through the
gapminderdata by continent and prints out whether the mean life expectancy is smaller or larger than 50 years.Solution to Challenge 3
Step 1: We want to make sure we can extract all the unique values of the continent vector
gapminder <- read.csv("data/gapminder_data.csv") unique(gapminder$continent)Step 2: We also need to loop over each of these continents and calculate the average life expectancy for each
subsetof data. We can do that as follows:
- Loop over each of the unique values of ‘continent’
- For each value of continent, create a temporary variable storing that subset
- Return the calculated life expectancy to the user by printing the output:
for (iContinent in unique(gapminder$continent)) { tmp <- gapminder[gapminder$continent == iContinent, ] cat(iContinent, mean(tmp$lifeExp, na.rm = TRUE), "\n") rm(tmp) }Step 3: The exercise only wants the output printed if the average life expectancy is less than 50 or greater than 50. So we need to add an
if()condition before printing, which evaluates whether the calculated average life expectancy is above or below a threshold, and prints an output conditional on the result. We need to amend (3) from above:3a. If the calculated life expectancy is less than some threshold (50 years), return the continent and a statement that life expectancy is less than threshold, otherwise return the continent and a statement that life expectancy is greater than threshold:
thresholdValue <- 50 for (iContinent in unique(gapminder$continent)) { tmp <- mean(gapminder[gapminder$continent == iContinent, "lifeExp"]) if (tmp < thresholdValue){ cat("Average Life Expectancy in", iContinent, "is less than", thresholdValue, "\n") } else { cat("Average Life Expectancy in", iContinent, "is greater than", thresholdValue, "\n") } # end if else condition rm(tmp) } # end for loop
Challenge 4
Modify the script from Challenge 3 to loop over each country. This time print out whether the life expectancy is smaller than 50, between 50 and 70, or greater than 70.
Solution to Challenge 4
We modify our solution to Challenge 3 by now adding two thresholds,
lowerThresholdandupperThresholdand extending our if-else statements:lowerThreshold <- 50 upperThreshold <- 70 for (iCountry in unique(gapminder$country)) { tmp <- mean(gapminder[gapminder$country == iCountry, "lifeExp"]) if(tmp < lowerThreshold) { cat("Average Life Expectancy in", iCountry, "is less than", lowerThreshold, "\n") } else if(tmp > lowerThreshold && tmp < upperThreshold) { cat("Average Life Expectancy in", iCountry, "is between", lowerThreshold, "and", upperThreshold, "\n") } else { cat("Average Life Expectancy in", iCountry, "is greater than", upperThreshold, "\n") } rm(tmp) }
Challenge 5 - Advanced
Write a script that loops over each country in the
gapminderdataset, tests whether the country starts with a ‘B’, and graphs life expectancy against time as a line graph if the mean life expectancy is under 50 years.Solution for Challenge 5
We will use the
grep()command that was introduced in the Unix Shell lesson to find countries that start with “B.” Lets understand how to do this first. Following from the Unix shell section we may be tempted to try the followinggrep("^B", unique(gapminder$country))But when we evaluate this command it returns the indices of the factor variable
countrythat start with “B.” To get the values, we must add thevalue=TRUEoption to thegrep()command:grep("^B", unique(gapminder$country), value = TRUE)We will now store these countries in a variable called candidateCountries, and then loop over each entry in the variable. Inside the loop, we evaluate the average life expectancy for each country, and if the average life expectancy is less than 50 we use base-plot to plot the evolution of average life expectancy using
with()andsubset():thresholdValue <- 50 candidateCountries <- grep("^B", unique(gapminder$country), value = TRUE) for (iCountry in candidateCountries) { tmp <- mean(gapminder[gapminder$country == iCountry, "lifeExp"]) if (tmp < thresholdValue) { cat("Average Life Expectancy in", iCountry, "is less than", thresholdValue, "plotting life expectancy graph... \n") with(subset(gapminder, country == iCountry), plot(year, lifeExp, type = "o", main = paste("Life Expectancy in", iCountry, "over time"), ylab = "Life Expectancy", xlab = "Year" ) # end plot ) # end with } # end if rm(tmp) } # end for loop
Key Points
Use
ifandelseto make choices.Use
forto repeat operations.
Vectorization
Overview
Teaching: 10 min
Exercises: 15 minQuestions
How can I operate on all the elements of a vector at once?
Objectives
To understand vectorized operations in R.
Most of R’s functions are vectorized, meaning that the function will operate on all elements of a vector without needing to loop through and act on each element one at a time. This makes writing code more concise, easy to read, and less error prone.
x <- 1:4
x * 2
[1] 2 4 6 8
The multiplication happened to each element of the vector.
We can also add two vectors together:
y <- 6:9
x + y
[1] 7 9 11 13
Each element of x was added to its corresponding element of y:
x: 1 2 3 4
+ + + +
y: 6 7 8 9
---------------
7 9 11 13
Here is how we would add two vectors together using a for loop:
output_vector <- c()
for (i in 1:4) {
output_vector[i] <- x[i] + y[i]
}
output_vector
[1] 7 9 11 13
Compare this to the output using vectorised operations.
sum_xy <- x + y
sum_xy
[1] 7 9 11 13
Challenge 1
Let’s try this on the
popcolumn of thegapminderdataset.Make a new column in the
gapminderdata frame that contains population in units of millions of people. Check the head or tail of the data frame to make sure it worked.Solution to challenge 1
Let’s try this on the
popcolumn of thegapminderdataset.Make a new column in the
gapminderdata frame that contains population in units of millions of people. Check the head or tail of the data frame to make sure it worked.gapminder$pop_millions <- gapminder$pop / 1e6 head(gapminder)country year pop continent lifeExp gdpPercap pop_millions 1 Afghanistan 1952 8425333 Asia 28.801 779.4453 8.425333 2 Afghanistan 1957 9240934 Asia 30.332 820.8530 9.240934 3 Afghanistan 1962 10267083 Asia 31.997 853.1007 10.267083 4 Afghanistan 1967 11537966 Asia 34.020 836.1971 11.537966 5 Afghanistan 1972 13079460 Asia 36.088 739.9811 13.079460 6 Afghanistan 1977 14880372 Asia 38.438 786.1134 14.880372
Challenge 2
On a single graph, plot population, in millions, against year, for all countries. Do not worry about identifying which country is which.
Repeat the exercise, graphing only for China, India, and Indonesia. Again, do not worry about which is which.
Solution to challenge 2
Refresh your plotting skills by plotting population in millions against year.
ggplot(gapminder, aes(x = year, y = pop_millions)) + geom_point()
countryset <- c("China","India","Indonesia") ggplot(gapminder[gapminder$country %in% countryset,], aes(x = year, y = pop_millions)) + geom_point()


Comparison operators, logical operators, and many functions are also vectorized:
Comparison operators
x > 2
[1] FALSE FALSE TRUE TRUE
Logical operators
a <- x > 3 # or, for clarity, a <- (x > 3)
a
[1] FALSE FALSE FALSE TRUE
Tip: some useful functions for logical vectors
any()will returnTRUEif any element of a vector isTRUE.
all()will returnTRUEif all elements of a vector areTRUE.
Most functions also operate element-wise on vectors:
Functions
x <- 1:4
log(x)
[1] 0.0000000 0.6931472 1.0986123 1.3862944
Vectorized operations work element-wise on matrices:
m <- matrix(1:12, nrow=3, ncol=4)
m * -1
[,1] [,2] [,3] [,4]
[1,] -1 -4 -7 -10
[2,] -2 -5 -8 -11
[3,] -3 -6 -9 -12
Tip: element-wise vs. matrix multiplication
Very important: the operator
*gives you element-wise multiplication! To do matrix multiplication, we need to use the%*%operator:m %*% matrix(1, nrow=4, ncol=1)[,1] [1,] 22 [2,] 26 [3,] 30matrix(1:4, nrow=1) %*% matrix(1:4, ncol=1)[,1] [1,] 30For more on matrix algebra, see the Quick-R reference guide
Challenge 3
Given the following matrix:
m <- matrix(1:12, nrow=3, ncol=4) m[,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12Write down what you think will happen when you run:
m ^ -1m * c(1, 0, -1)m > c(0, 20)m * c(1, 0, -1, 2)Did you get the output you expected? If not, ask a helper!
Solution to challenge 3
Given the following matrix:
m <- matrix(1:12, nrow=3, ncol=4) m[,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12Write down what you think will happen when you run:
m ^ -1[,1] [,2] [,3] [,4] [1,] 1.0000000 0.2500000 0.1428571 0.10000000 [2,] 0.5000000 0.2000000 0.1250000 0.09090909 [3,] 0.3333333 0.1666667 0.1111111 0.08333333
m * c(1, 0, -1)[,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 0 0 0 0 [3,] -3 -6 -9 -12
m > c(0, 20)[,1] [,2] [,3] [,4] [1,] TRUE FALSE TRUE FALSE [2,] FALSE TRUE FALSE TRUE [3,] TRUE FALSE TRUE FALSE
Challenge 4
We’re interested in looking at the sum of the following sequence of fractions:
x = 1/(1^2) + 1/(2^2) + 1/(3^2) + ... + 1/(n^2)This would be tedious to type out, and impossible for high values of n. Use vectorisation to compute x when n=100. What is the sum when n=10,000?
Challenge 4
We’re interested in looking at the sum of the following sequence of fractions:
x = 1/(1^2) + 1/(2^2) + 1/(3^2) + ... + 1/(n^2)This would be tedious to type out, and impossible for high values of n. Can you use vectorisation to compute x, when n=100? How about when n=10,000?
sum(1/(1:100)^2)[1] 1.634984sum(1/(1:1e04)^2)[1] 1.644834n <- 10000 sum(1/(1:n)^2)[1] 1.644834We can also obtain the same results using a function:
inverse_sum_of_squares <- function(n) { sum(1/(1:n)^2) } inverse_sum_of_squares(100)[1] 1.634984inverse_sum_of_squares(10000)[1] 1.644834n <- 10000 inverse_sum_of_squares(n)[1] 1.644834
Key Points
Use vectorized operations instead of loops.
Functions Explained
Overview
Teaching: 45 min
Exercises: 15 minQuestions
How can I write a new function in R?
Objectives
Define a function that takes arguments.
Return a value from a function.
Check argument conditions with
stopifnot()in functions.Test a function.
Set default values for function arguments.
Explain why we should divide programs into small, single-purpose functions.
If we only had one data set to analyze, it would probably be faster to load the file into a spreadsheet and use that to plot simple statistics. However, the gapminder data is updated periodically, and we may want to pull in that new information later and re-run our analysis again. We may also obtain similar data from a different source in the future.
In this lesson, we’ll learn how to write a function so that we can repeat several operations with a single command.
What is a function?
Functions gather a sequence of operations into a whole, preserving it for ongoing use. Functions provide:
- a name we can remember and invoke it by
- relief from the need to remember the individual operations
- a defined set of inputs and expected outputs
- rich connections to the larger programming environment
As the basic building block of most programming languages, user-defined functions constitute “programming” as much as any single abstraction can. If you have written a function, you are a computer programmer.
Defining a function
Let’s open a new R script file in the functions/ directory and call it
functions-lesson.R.
Let’s define a function fahr_to_kelvin() that converts temperatures from
Fahrenheit to Kelvin:
fahr_to_kelvin <- function(temp) {
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
We define fahr_to_kelvin() by assigning it to the output of function. The
list of argument names are contained within parentheses. Next, the
body of the function–the
statements that are executed when it runs–is contained within curly braces
({}). The statements in the body are indented by two spaces. This makes the
code easier to read but does not affect how the code operates.
It is useful to think of creating functions like writing a cookbook. First you define the “ingredients” that your function needs. In this case, we only need one ingredient to use our function: “temp”. After we list our ingredients, we then say what we will do with them, in this case, we are taking our ingredient and applying a set of mathematical operators to it.
When we call the function, the values we pass to it as arguments are assigned to those variables so that we can use them inside the function. Inside the function, we use a return statement to send a result back to whoever asked for it.
Tip
One feature unique to R is that the return statement is not required. R automatically returns whichever variable is on the last line of the body of the function. But for clarity, we will explicitly define the return statement.
Let’s try running our function. Calling our own function is no different from calling any other function:
# freezing point of water
fahr_to_kelvin(32)
[1] 273.15
# boiling point of water
fahr_to_kelvin(212)
[1] 373.15
Challenge 1
Write a function called
kelvin_to_celsius()that takes a temperature in Kelvin and returns that temperature in Celsius.Hint: To convert from Kelvin to Celsius you subtract 273.15
Solution to challenge 1
Write a function called
kelvin_to_celsiusthat takes a temperature in Kelvin and returns that temperature in Celsiuskelvin_to_celsius <- function(temp) { celsius <- temp - 273.15 return(celsius) }
Combining functions
The real power of functions comes from mixing, matching and combining them into ever-larger chunks to get the effect we want.
Let’s define two functions that will convert temperature from Fahrenheit to Kelvin, and Kelvin to Celsius:
fahr_to_kelvin <- function(temp) {
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
kelvin_to_celsius <- function(temp) {
celsius <- temp - 273.15
return(celsius)
}
Challenge 2
Define the function to convert directly from Fahrenheit to Celsius, by reusing the two functions above (or using your own functions if you prefer).
Solution to challenge 2
Define the function to convert directly from Fahrenheit to Celsius, by reusing these two functions above
fahr_to_celsius <- function(temp) { temp_k <- fahr_to_kelvin(temp) result <- kelvin_to_celsius(temp_k) return(result) }
Interlude: Defensive Programming
Now that we’ve begun to appreciate how writing functions provides an efficient
way to make R code re-usable and modular, we should note that it is important
to ensure that functions only work in their intended use-cases. Checking
function parameters is related to the concept of defensive programming.
Defensive programming encourages us to frequently check conditions and throw an
error if something is wrong. These checks are referred to as assertion
statements because we want to assert some condition is TRUE before proceeding.
They make it easier to debug because they give us a better idea of where the
errors originate.
Checking conditions with stopifnot()
Let’s start by re-examining fahr_to_kelvin(), our function for converting
temperatures from Fahrenheit to Kelvin. It was defined like so:
fahr_to_kelvin <- function(temp) {
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
For this function to work as intended, the argument temp must be a numeric
value; otherwise, the mathematical procedure for converting between the two
temperature scales will not work. To create an error, we can use the function
stop(). For example, since the argument temp must be a numeric vector, we
could check for this condition with an if statement and throw an error if the
condition was violated. We could augment our function above like so:
fahr_to_kelvin <- function(temp) {
if (!is.numeric(temp)) {
stop("temp must be a numeric vector.")
}
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
If we had multiple conditions or arguments to check, it would take many lines
of code to check all of them. Luckily R provides the convenience function
stopifnot(). We can list as many requirements that should evaluate to TRUE;
stopifnot() throws an error if it finds one that is FALSE. Listing these
conditions also serves a secondary purpose as extra documentation for the
function.
Let’s try out defensive programming with stopifnot() by adding assertions to
check the input to our function fahr_to_kelvin().
We want to assert the following: temp is a numeric vector. We may do that like
so:
fahr_to_kelvin <- function(temp) {
stopifnot(is.numeric(temp))
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
It still works when given proper input.
# freezing point of water
fahr_to_kelvin(temp = 32)
[1] 273.15
But fails instantly if given improper input.
# Metric is a factor instead of numeric
fahr_to_kelvin(temp = as.factor(32))
Error in fahr_to_kelvin(temp = as.factor(32)): is.numeric(temp) is not TRUE
Challenge 3
Use defensive programming to ensure that our
fahr_to_celsius()function throws an error immediately if the argumenttempis specified inappropriately.Solution to challenge 3
Extend our previous definition of the function by adding in an explicit call to
stopifnot(). Sincefahr_to_celsius()is a composition of two other functions, checking inside here makes adding checks to the two component functions redundant.fahr_to_celsius <- function(temp) { stopifnot(is.numeric(temp)) temp_k <- fahr_to_kelvin(temp) result <- kelvin_to_celsius(temp_k) return(result) }
More on combining functions
Now, we’re going to define a function that calculates the Gross Domestic Product of a nation from the data available in our dataset:
# Takes a dataset and multiplies the population column
# with the GDP per capita column.
calcGDP <- function(dat) {
gdp <- dat$pop * dat$gdpPercap
return(gdp)
}
We define calcGDP() by assigning it to the output of function. The list of
argument names are contained within parentheses. Next, the body of the function
– the statements executed when you call the function – is contained within
curly braces ({}).
We’ve indented the statements in the body by two spaces. This makes the code easier to read but does not affect how it operates.
When we call the function, the values we pass to it are assigned to the arguments, which become variables inside the body of the function.
Inside the function, we use the return() function to send back the result.
This return() function is optional: R will automatically return the results of
whatever command is executed on the last line of the function.
calcGDP(head(gapminder))
[1] 6567086330 7585448670 8758855797 9648014150 9678553274 11697659231
That’s not very informative. Let’s add some more arguments so we can extract that per year and country.
# Takes a dataset and multiplies the population column
# with the GDP per capita column.
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}
If you’ve been writing these functions down into a separate R script
(a good idea!), you can load in the functions into our R session by using the
source() function:
source("functions/functions-lesson.R")
Ok, so there’s a lot going on in this function now. In plain English, the function now subsets the provided data by year if the year argument isn’t empty, then subsets the result by country if the country argument isn’t empty. Then it calculates the GDP for whatever subset emerges from the previous two steps. The function then adds the GDP as a new column to the subsetted data and returns this as the final result. You can see that the output is much more informative than a vector of numbers.
Let’s take a look at what happens when we specify the year:
head(calcGDP(gapminder, year=2007))
country year pop continent lifeExp gdpPercap gdp
12 Afghanistan 2007 31889923 Asia 43.828 974.5803 31079291949
24 Albania 2007 3600523 Europe 76.423 5937.0295 21376411360
36 Algeria 2007 33333216 Africa 72.301 6223.3675 207444851958
48 Angola 2007 12420476 Africa 42.731 4797.2313 59583895818
60 Argentina 2007 40301927 Americas 75.320 12779.3796 515033625357
72 Australia 2007 20434176 Oceania 81.235 34435.3674 703658358894
Or for a specific country:
calcGDP(gapminder, country="Australia")
country year pop continent lifeExp gdpPercap gdp
61 Australia 1952 8691212 Oceania 69.120 10039.60 87256254102
62 Australia 1957 9712569 Oceania 70.330 10949.65 106349227169
63 Australia 1962 10794968 Oceania 70.930 12217.23 131884573002
64 Australia 1967 11872264 Oceania 71.100 14526.12 172457986742
65 Australia 1972 13177000 Oceania 71.930 16788.63 221223770658
66 Australia 1977 14074100 Oceania 73.490 18334.20 258037329175
67 Australia 1982 15184200 Oceania 74.740 19477.01 295742804309
68 Australia 1987 16257249 Oceania 76.320 21888.89 355853119294
69 Australia 1992 17481977 Oceania 77.560 23424.77 409511234952
70 Australia 1997 18565243 Oceania 78.830 26997.94 501223252921
71 Australia 2002 19546792 Oceania 80.370 30687.75 599847158654
72 Australia 2007 20434176 Oceania 81.235 34435.37 703658358894
Or both:
calcGDP(gapminder, year=2007, country="Australia")
country year pop continent lifeExp gdpPercap gdp
72 Australia 2007 20434176 Oceania 81.235 34435.37 703658358894
Let’s walk through the body of the function:
calcGDP <- function(dat, year=NULL, country=NULL) {
Here we’ve added two arguments, year, and country. We’ve set
default arguments for both as NULL using the = operator
in the function definition. This means that those arguments will
take on those values unless the user specifies otherwise.
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
Here, we check whether each additional argument is set to null, and whenever
they’re not null overwrite the dataset stored in dat with a subset given by
the non-null argument.
Building these conditionals into the function makes it more flexible for later. Now, we can use it to calculate the GDP for:
- The whole dataset;
- A single year;
- A single country;
- A single combination of year and country.
By using %in% instead, we can also give multiple years or countries to those
arguments.
Tip: Pass by value
Functions in R almost always make copies of the data to operate on inside of a function body. When we modify
datinside the function we are modifying the copy of the gapminder dataset stored indat, not the original variable we gave as the first argument.This is called “pass-by-value” and it makes writing code much safer: you can always be sure that whatever changes you make within the body of the function, stay inside the body of the function.
Tip: Function scope
Another important concept is scoping: any variables (or functions!) you create or modify inside the body of a function only exist for the lifetime of the function’s execution. When we call
calcGDP(), the variablesdat,gdpandnewonly exist inside the body of the function. Even if we have variables of the same name in our interactive R session, they are not modified in any way when executing a function.
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}
Finally, we calculated the GDP on our new subset, and created a new data frame with that column added. This means when we call the function later we can see the context for the returned GDP values, which is much better than in our first attempt where we got a vector of numbers.
Challenge 4
Test out your GDP function by calculating the GDP for New Zealand in 1987. How does this differ from New Zealand’s GDP in 1952?
Solution to challenge 4
calcGDP(gapminder, year = c(1952, 1987), country = "New Zealand")GDP for New Zealand in 1987: 65050008703
GDP for New Zealand in 1952: 21058193787
Challenge 5
The
paste()function can be used to combine text together, e.g:best_practice <- c("Write", "programs", "for", "people", "not", "computers") paste(best_practice, collapse=" ")[1] "Write programs for people not computers"Write a function called
fence()that takes two vectors as arguments, calledtextandwrapper, and prints out the text wrapped with thewrapper:fence(text=best_practice, wrapper="***")Note: the
paste()function has an argument calledsep, which specifies the separator between text. The default is a space: “ “. The default forpaste0()is no space “”.Solution to challenge 5
Write a function called
fence()that takes two vectors as arguments, calledtextandwrapper, and prints out the text wrapped with thewrapper:fence <- function(text, wrapper){ text <- c(wrapper, text, wrapper) result <- paste(text, collapse = " ") return(result) } best_practice <- c("Write", "programs", "for", "people", "not", "computers") fence(text=best_practice, wrapper="***")[1] "*** Write programs for people not computers ***"
Tip
R has some unique aspects that can be exploited when performing more complicated operations. We will not be writing anything that requires knowledge of these more advanced concepts. In the future when you are comfortable writing functions in R, you can learn more by reading the R Language Manual or this chapter from Advanced R Programming by Hadley Wickham.
Tip: Testing and documenting
It’s important to both test functions and document them: Documentation helps you, and others, understand what the purpose of your function is, and how to use it, and its important to make sure that your function actually does what you think.
When you first start out, your workflow will probably look a lot like this:
- Write a function
- Comment parts of the function to document its behaviour
- Load in the source file
- Experiment with it in the console to make sure it behaves as you expect
- Make any necessary bug fixes
- Rinse and repeat.
Formal documentation for functions, written in separate
.Rdfiles, gets turned into the documentation you see in help files. The roxygen2 package allows R coders to write documentation alongside the function code and then process it into the appropriate.Rdfiles. You will want to switch to this more formal method of writing documentation when you start writing more complicated R projects.Formal automated tests can be written using the testthat package.
Key Points
Use
functionto define a new function in R.Use parameters to pass values into functions.
Use
stopifnot()to flexibly check function arguments in R.Load functions into programs using
source().
Data Wrangling with dplyr and tidyr
Overview
Teaching: 50 min
Exercises: 30 minQuestions
How can I select specific rows and/or columns from a dataframe?
How can I combine multiple commands into a single command?
How can I create new columns or remove existing columns from a dataframe?
How can I reformat a dataframe to meet my needs?
Objectives
Describe the purpose of an R package and the
dplyrandtidyrpackages.Select certain columns in a dataframe with the
dplyrfunctionselect.Select certain rows in a dataframe according to filtering conditions with the
dplyrfunctionfilter.Link the output of one
dplyrfunction to the input of another function with the ‘pipe’ operator%>%.Add new columns to a dataframe that are functions of existing columns with
mutate.Use the split-apply-combine concept for data analysis.
Use
summarize,group_by, andcountto split a dataframe into groups of observations, apply a summary statistics for each group, and then combine the results.Describe the concept of a wide and a long table format and for which purpose those formats are useful.
Describe the roles of variable names and their associated values when a table is reshaped.
Reshape a dataframe from long to wide format and back with the
pivot_widerandpivot_longercommands from thetidyrpackage.Export a dataframe to a csv file.
dplyr is a package for making tabular data wrangling easier by using a
limited set of functions that can be combined to extract and summarize insights
from your data. It pairs nicely with tidyr which enables you to swiftly
convert between different data formats (long vs. wide) for plotting and analysis.
Similarly to readr, dplyr and tidyr are also part of the
tidyverse. These packages were loaded in R’s memory when we called
library(tidyverse) earlier.
Note
The packages in the tidyverse, namely
dplyr,tidyrandggplot2accept both the British (e.g. summarise) and American (e.g. summarize) spelling variants of different function and option names. For this lesson, we utilize the American spellings of different functions; however, feel free to use the regional variant for where you are teaching.
What is an R package?
The package dplyr provides easy tools for the most common data
wrangling tasks. It is built to work directly with dataframes, with many
common tasks optimized by being written in a compiled language (C++) (not all R
packages are written in R!).
The package tidyr addresses the common problem of wanting to reshape your
data for plotting and use by different R functions. Sometimes we want data sets
where we have one row per measurement. Sometimes we want a dataframe where each
measurement type has its own column, and rows are instead more aggregated
groups. Moving back and forth between these formats is nontrivial, and
tidyr gives you tools for this and more sophisticated data wrangling.
But there are also packages available for a wide range of tasks including
building plots (ggplot2, which we’ll see later), downloading data from the
NCBI database, or performing statistical analysis on your data set. Many
packages such as these are housed on, and downloadable from, the
Comprehensive R Archive Network (CRAN) using install.packages.
This function makes the package accessible by your R installation with the
command library(), as you did with tidyverse earlier.
To easily access the documentation for a package within R or RStudio, use
help(package = "package_name").
To learn more about dplyr and tidyr after the workshop, you may want
to check out this handy data transformation with dplyr cheatsheet
and this one about tidyr.
Learning dplyr and tidyr
To make sure everyone will use the same dataset for this lesson, we’ll read again the SAFI dataset that we downloaded earlier.
## load the tidyverse
library(tidyverse)
interviews <- read_csv("data/SAFI_clean.csv", na = "NULL")
## inspect the data
interviews
## preview the data
# view(interviews)
We’re going to learn some of the most common dplyr functions:
select(): subset columnsfilter(): subset rows on conditionsmutate(): create new columns by using information from other columnsgroup_by()andsummarize(): create summary statistics on grouped dataarrange(): sort resultscount(): count discrete values
Selecting columns and filtering rows
To select columns of a dataframe, use select(). The first argument to this
function is the dataframe (interviews), and the subsequent arguments are the
columns to keep, separated by commas. Alternatively, if you are selecting
columns adjacent to each other, you can use a : to select a range of columns,
read as “select columns from __ to __.”
# to select columns throughout the dataframe
select(interviews, village, no_membrs, months_lack_food)
# to select a series of connected columns
select(interviews, village:respondent_wall_type)
To choose rows based on specific criteria, we can use the filter() function.
The argument after the dataframe is the condition we want our final
dataframe to adhere to (e.g. village name is Chirodzo):
# filters observations where village name is "Chirodzo"
filter(interviews, village == "Chirodzo")
# A tibble: 39 x 14
key_ID village interview_date no_membrs years_liv respondent_wall… rooms
<dbl> <chr> <dttm> <dbl> <dbl> <chr> <dbl>
1 8 Chirod… 2016-11-16 00:00:00 12 70 burntbricks 3
2 9 Chirod… 2016-11-16 00:00:00 8 6 burntbricks 1
3 10 Chirod… 2016-12-16 00:00:00 12 23 burntbricks 5
4 34 Chirod… 2016-11-17 00:00:00 8 18 burntbricks 3
5 35 Chirod… 2016-11-17 00:00:00 5 45 muddaub 1
6 36 Chirod… 2016-11-17 00:00:00 6 23 sunbricks 1
7 37 Chirod… 2016-11-17 00:00:00 3 8 burntbricks 1
8 43 Chirod… 2016-11-17 00:00:00 7 29 muddaub 1
9 44 Chirod… 2016-11-17 00:00:00 2 6 muddaub 1
10 45 Chirod… 2016-11-17 00:00:00 9 7 muddaub 1
# … with 29 more rows, and 7 more variables: memb_assoc <chr>,
# affect_conflicts <chr>, liv_count <dbl>, items_owned <chr>, no_meals <dbl>,
# months_lack_food <chr>, instanceID <chr>
We can also specify multiple conditions within the filter() function. We can
combine conditions using either “and” or “or” statements. In an “and”
statement, an observation (row) must meet every criteria to be included
in the resulting dataframe. To form “and” statements within dplyr, we can pass
our desired conditions as arguments in the filter() function, separated by
commas:
# filters observations with "and" operator (comma)
# output dataframe satisfies ALL specified conditions
filter(interviews, village == "Chirodzo",
rooms > 1,
no_meals > 2)
# A tibble: 10 x 14
key_ID village interview_date no_membrs years_liv respondent_wall… rooms
<dbl> <chr> <dttm> <dbl> <dbl> <chr> <dbl>
1 10 Chirod… 2016-12-16 00:00:00 12 23 burntbricks 5
2 49 Chirod… 2016-11-16 00:00:00 6 26 burntbricks 2
3 52 Chirod… 2016-11-16 00:00:00 11 15 burntbricks 3
4 56 Chirod… 2016-11-16 00:00:00 12 23 burntbricks 2
5 65 Chirod… 2016-11-16 00:00:00 8 20 burntbricks 3
6 66 Chirod… 2016-11-16 00:00:00 10 37 burntbricks 3
7 67 Chirod… 2016-11-16 00:00:00 5 31 burntbricks 2
8 68 Chirod… 2016-11-16 00:00:00 8 52 burntbricks 3
9 199 Chirod… 2017-06-04 00:00:00 7 17 burntbricks 2
10 200 Chirod… 2017-06-04 00:00:00 8 20 burntbricks 2
# … with 7 more variables: memb_assoc <chr>, affect_conflicts <chr>,
# liv_count <dbl>, items_owned <chr>, no_meals <dbl>, months_lack_food <chr>,
# instanceID <chr>
We can also form “and” statements with the & operator instead of commas:
# filters observations with "&" logical operator
# output dataframe satisfies ALL specified conditions
filter(interviews, village == "Chirodzo" &
rooms > 1 &
no_meals > 2)
# A tibble: 10 x 14
key_ID village interview_date no_membrs years_liv respondent_wall… rooms
<dbl> <chr> <dttm> <dbl> <dbl> <chr> <dbl>
1 10 Chirod… 2016-12-16 00:00:00 12 23 burntbricks 5
2 49 Chirod… 2016-11-16 00:00:00 6 26 burntbricks 2
3 52 Chirod… 2016-11-16 00:00:00 11 15 burntbricks 3
4 56 Chirod… 2016-11-16 00:00:00 12 23 burntbricks 2
5 65 Chirod… 2016-11-16 00:00:00 8 20 burntbricks 3
6 66 Chirod… 2016-11-16 00:00:00 10 37 burntbricks 3
7 67 Chirod… 2016-11-16 00:00:00 5 31 burntbricks 2
8 68 Chirod… 2016-11-16 00:00:00 8 52 burntbricks 3
9 199 Chirod… 2017-06-04 00:00:00 7 17 burntbricks 2
10 200 Chirod… 2017-06-04 00:00:00 8 20 burntbricks 2
# … with 7 more variables: memb_assoc <chr>, affect_conflicts <chr>,
# liv_count <dbl>, items_owned <chr>, no_meals <dbl>, months_lack_food <chr>,
# instanceID <chr>
In an “or” statement, observations must meet at least one of the specified conditions. To form “or” statements we use the logical operator for “or,” which is the vertical bar (|):
# filters observations with "|" logical operator
# output dataframe satisfies AT LEAST ONE of the specified conditions
filter(interviews, village == "Chirodzo" | village == "Ruaca")
# A tibble: 88 x 14
key_ID village interview_date no_membrs years_liv respondent_wall… rooms
<dbl> <chr> <dttm> <dbl> <dbl> <chr> <dbl>
1 8 Chirod… 2016-11-16 00:00:00 12 70 burntbricks 3
2 9 Chirod… 2016-11-16 00:00:00 8 6 burntbricks 1
3 10 Chirod… 2016-12-16 00:00:00 12 23 burntbricks 5
4 23 Ruaca 2016-11-21 00:00:00 10 20 burntbricks 4
5 24 Ruaca 2016-11-21 00:00:00 6 4 burntbricks 2
6 25 Ruaca 2016-11-21 00:00:00 11 6 burntbricks 3
7 26 Ruaca 2016-11-21 00:00:00 3 20 burntbricks 2
8 27 Ruaca 2016-11-21 00:00:00 7 36 burntbricks 2
9 28 Ruaca 2016-11-21 00:00:00 2 2 muddaub 1
10 29 Ruaca 2016-11-21 00:00:00 7 10 burntbricks 2
# … with 78 more rows, and 7 more variables: memb_assoc <chr>,
# affect_conflicts <chr>, liv_count <dbl>, items_owned <chr>, no_meals <dbl>,
# months_lack_food <chr>, instanceID <chr>
Pipes
What if you want to select and filter at the same time? There are three ways to do this: use intermediate steps, nested functions, or pipes.
With intermediate steps, you create a temporary dataframe and use that as input to the next function, like this:
interviews2 <- filter(interviews, village == "Chirodzo")
interviews_ch <- select(interviews2, village:respondent_wall_type)
This is readable, but can clutter up your workspace with lots of objects that you have to name individually. With multiple steps, that can be hard to keep track of.
You can also nest functions (i.e. one function inside of another), like this:
interviews_ch <- select(filter(interviews, village == "Chirodzo"),
village:respondent_wall_type)
This is handy, but can be difficult to read if too many functions are nested, as R evaluates the expression from the inside out (in this case, filtering, then selecting).
The last option, pipes, are a recent addition to R. Pipes let you take the
output of one function and send it directly to the next, which is useful when
you need to do many things to the same dataset. Pipes in R look like %>% and
are made available via the magrittr package, installed automatically with
dplyr. If you use RStudio, you can type the pipe with:
- Ctrl + Shift + M if you have a PC or Cmd + Shift + M if you have a Mac.
interviews %>%
filter(village == "Chirodzo") %>%
select(village:respondent_wall_type)
# A tibble: 39 x 5
village interview_date no_membrs years_liv respondent_wall_type
<chr> <dttm> <dbl> <dbl> <chr>
1 Chirodzo 2016-11-16 00:00:00 12 70 burntbricks
2 Chirodzo 2016-11-16 00:00:00 8 6 burntbricks
3 Chirodzo 2016-12-16 00:00:00 12 23 burntbricks
4 Chirodzo 2016-11-17 00:00:00 8 18 burntbricks
5 Chirodzo 2016-11-17 00:00:00 5 45 muddaub
6 Chirodzo 2016-11-17 00:00:00 6 23 sunbricks
7 Chirodzo 2016-11-17 00:00:00 3 8 burntbricks
8 Chirodzo 2016-11-17 00:00:00 7 29 muddaub
9 Chirodzo 2016-11-17 00:00:00 2 6 muddaub
10 Chirodzo 2016-11-17 00:00:00 9 7 muddaub
# … with 29 more rows
In the above code, we use the pipe to send the interviews dataset first
through filter() to keep rows where village is “Chirodzo”, then through
select() to keep only the no_membrs and years_liv columns. Since %>%
takes the object on its left and passes it as the first argument to the function
on its right, we don’t need to explicitly include the dataframe as an argument
to the filter() and select() functions any more.
Some may find it helpful to read the pipe like the word “then”. For instance,
in the above example, we take the dataframe interviews, then we filter
for rows with village == "Chirodzo", then we select columns no_membrs and
years_liv. The dplyr functions by themselves are somewhat simple,
but by combining them into linear workflows with the pipe, we can accomplish
more complex data wrangling operations.
If we want to create a new object with this smaller version of the data, we can assign it a new name:
interviews_ch <- interviews %>%
filter(village == "Chirodzo") %>%
select(village:respondent_wall_type)
interviews_ch
# A tibble: 39 x 5
village interview_date no_membrs years_liv respondent_wall_type
<chr> <dttm> <dbl> <dbl> <chr>
1 Chirodzo 2016-11-16 00:00:00 12 70 burntbricks
2 Chirodzo 2016-11-16 00:00:00 8 6 burntbricks
3 Chirodzo 2016-12-16 00:00:00 12 23 burntbricks
4 Chirodzo 2016-11-17 00:00:00 8 18 burntbricks
5 Chirodzo 2016-11-17 00:00:00 5 45 muddaub
6 Chirodzo 2016-11-17 00:00:00 6 23 sunbricks
7 Chirodzo 2016-11-17 00:00:00 3 8 burntbricks
8 Chirodzo 2016-11-17 00:00:00 7 29 muddaub
9 Chirodzo 2016-11-17 00:00:00 2 6 muddaub
10 Chirodzo 2016-11-17 00:00:00 9 7 muddaub
# … with 29 more rows
Note that the final dataframe (interviews_ch) is the leftmost part of this
expression.
Exercise
Using pipes, subset the
interviewsdata to include interviews where respondents were members of an irrigation association (memb_assoc) and retain only the columnsaffect_conflicts,liv_count, andno_meals.Solution
interviews %>% filter(memb_assoc == "yes") %>% select(affect_conflicts, liv_count, no_meals)# A tibble: 33 x 3 affect_conflicts liv_count no_meals <chr> <dbl> <dbl> 1 once 3 2 2 never 2 2 3 never 2 3 4 once 3 2 5 frequently 1 3 6 more_once 5 2 7 more_once 3 2 8 more_once 2 3 9 once 3 3 10 never 3 3 # … with 23 more rows
Mutate
Frequently you’ll want to create new columns based on the values in existing
columns, for example to do unit conversions, or to find the ratio of values in
two columns. For this we’ll use mutate().
We might be interested in the ratio of number of household members to rooms used for sleeping (i.e. avg number of people per room):
interviews %>%
mutate(people_per_room = no_membrs / rooms)
# A tibble: 131 x 15
key_ID village interview_date no_membrs years_liv respondent_wall… rooms
<dbl> <chr> <dttm> <dbl> <dbl> <chr> <dbl>
1 1 God 2016-11-17 00:00:00 3 4 muddaub 1
2 1 God 2016-11-17 00:00:00 7 9 muddaub 1
3 3 God 2016-11-17 00:00:00 10 15 burntbricks 1
4 4 God 2016-11-17 00:00:00 7 6 burntbricks 1
5 5 God 2016-11-17 00:00:00 7 40 burntbricks 1
6 6 God 2016-11-17 00:00:00 3 3 muddaub 1
7 7 God 2016-11-17 00:00:00 6 38 muddaub 1
8 8 Chirod… 2016-11-16 00:00:00 12 70 burntbricks 3
9 9 Chirod… 2016-11-16 00:00:00 8 6 burntbricks 1
10 10 Chirod… 2016-12-16 00:00:00 12 23 burntbricks 5
# … with 121 more rows, and 8 more variables: memb_assoc <chr>,
# affect_conflicts <chr>, liv_count <dbl>, items_owned <chr>, no_meals <dbl>,
# months_lack_food <chr>, instanceID <chr>, people_per_room <dbl>
We may be interested in investigating whether being a member of an irrigation association had any effect on the ratio of household members to rooms. To look at this relationship, we will first remove data from our dataset where the respondent didn’t answer the question of whether they were a member of an irrigation association. These cases are recorded as “NULL” in the dataset.
To remove these cases, we could insert a filter() in the chain:
interviews %>%
filter(!is.na(memb_assoc)) %>%
mutate(people_per_room = no_membrs / rooms)
# A tibble: 92 x 15
key_ID village interview_date no_membrs years_liv respondent_wall… rooms
<dbl> <chr> <dttm> <dbl> <dbl> <chr> <dbl>
1 1 God 2016-11-17 00:00:00 7 9 muddaub 1
2 7 God 2016-11-17 00:00:00 6 38 muddaub 1
3 8 Chirod… 2016-11-16 00:00:00 12 70 burntbricks 3
4 9 Chirod… 2016-11-16 00:00:00 8 6 burntbricks 1
5 10 Chirod… 2016-12-16 00:00:00 12 23 burntbricks 5
6 12 God 2016-11-21 00:00:00 7 20 burntbricks 3
7 13 God 2016-11-21 00:00:00 6 8 burntbricks 1
8 15 God 2016-11-21 00:00:00 5 30 sunbricks 2
9 21 God 2016-11-21 00:00:00 8 20 burntbricks 1
10 24 Ruaca 2016-11-21 00:00:00 6 4 burntbricks 2
# … with 82 more rows, and 8 more variables: memb_assoc <chr>,
# affect_conflicts <chr>, liv_count <dbl>, items_owned <chr>, no_meals <dbl>,
# months_lack_food <chr>, instanceID <chr>, people_per_room <dbl>
The ! symbol negates the result of the is.na() function. Thus, if is.na()
returns a value of TRUE (because the memb_assoc is missing), the ! symbol
negates this and says we only want values of FALSE, where memb_assoc is
not missing.
Exercise
Create a new dataframe from the
interviewsdata that meets the following criteria: contains only thevillagecolumn and a new column calledtotal_mealscontaining a value that is equal to the total number of meals served in the household per day on average (no_membrstimesno_meals). Only the rows wheretotal_mealsis greater than 20 should be shown in the final dataframe.Hint: think about how the commands should be ordered to produce this data frame!
Solution
interviews_total_meals <- interviews %>% mutate(total_meals = no_membrs * no_meals) %>% filter(total_meals > 20) %>% select(village, total_meals)
Split-apply-combine data analysis and the summarize() function
Many data analysis tasks can be approached using the split-apply-combine
paradigm: split the data into groups, apply some analysis to each group, and
then combine the results. dplyr makes this very easy through the use of
the group_by() function.
The summarize() function
group_by() is often used together with summarize(), which collapses each
group into a single-row summary of that group. group_by() takes as arguments
the column names that contain the categorical variables for which you want
to calculate the summary statistics. So to compute the average household size by
village:
interviews %>%
group_by(village) %>%
summarize(mean_no_membrs = mean(no_membrs))
# A tibble: 3 x 2
village mean_no_membrs
<chr> <dbl>
1 Chirodzo 7.08
2 God 6.86
3 Ruaca 7.57
You may also have noticed that the output from these calls doesn’t run off the
screen anymore. It’s one of the advantages of tbl_df over dataframe.
You can also group by multiple columns:
interviews %>%
group_by(village, memb_assoc) %>%
summarize(mean_no_membrs = mean(no_membrs))
`summarise()` has grouped output by 'village'. You can override using the `.groups` argument.
# A tibble: 9 x 3
# Groups: village [3]
village memb_assoc mean_no_membrs
<chr> <chr> <dbl>
1 Chirodzo no 8.06
2 Chirodzo yes 7.82
3 Chirodzo <NA> 5.08
4 God no 7.13
5 God yes 8
6 God <NA> 6
7 Ruaca no 7.18
8 Ruaca yes 9.5
9 Ruaca <NA> 6.22
Note that the output is a grouped tibble. To obtain an ungrouped tibble, use the
ungroup function:
interviews %>%
group_by(village, memb_assoc) %>%
summarize(mean_no_membrs = mean(no_membrs)) %>%
ungroup()
`summarise()` has grouped output by 'village'. You can override using the `.groups` argument.
# A tibble: 9 x 3
village memb_assoc mean_no_membrs
<chr> <chr> <dbl>
1 Chirodzo no 8.06
2 Chirodzo yes 7.82
3 Chirodzo <NA> 5.08
4 God no 7.13
5 God yes 8
6 God <NA> 6
7 Ruaca no 7.18
8 Ruaca yes 9.5
9 Ruaca <NA> 6.22
When grouping both by village and membr_assoc, we see rows in our table for
respondents who did not specify whether they were a member of an irrigation
association. We can exclude those data from our table using a filter step.
interviews %>%
filter(!is.na(memb_assoc)) %>%
group_by(village, memb_assoc) %>%
summarize(mean_no_membrs = mean(no_membrs))
`summarise()` has grouped output by 'village'. You can override using the `.groups` argument.
# A tibble: 6 x 3
# Groups: village [3]
village memb_assoc mean_no_membrs
<chr> <chr> <dbl>
1 Chirodzo no 8.06
2 Chirodzo yes 7.82
3 God no 7.13
4 God yes 8
5 Ruaca no 7.18
6 Ruaca yes 9.5
Once the data are grouped, you can also summarize multiple variables at the same time (and not necessarily on the same variable). For instance, we could add a column indicating the minimum household size for each village for each group (members of an irrigation association vs not):
interviews %>%
filter(!is.na(memb_assoc)) %>%
group_by(village, memb_assoc) %>%
summarize(mean_no_membrs = mean(no_membrs),
min_membrs = min(no_membrs))
`summarise()` has grouped output by 'village'. You can override using the `.groups` argument.
# A tibble: 6 x 4
# Groups: village [3]
village memb_assoc mean_no_membrs min_membrs
<chr> <chr> <dbl> <dbl>
1 Chirodzo no 8.06 4
2 Chirodzo yes 7.82 2
3 God no 7.13 3
4 God yes 8 5
5 Ruaca no 7.18 2
6 Ruaca yes 9.5 5
It is sometimes useful to rearrange the result of a query to inspect the values.
For instance, we can sort on min_membrs to put the group with the smallest
household first:
interviews %>%
filter(!is.na(memb_assoc)) %>%
group_by(village, memb_assoc) %>%
summarize(mean_no_membrs = mean(no_membrs),
min_membrs = min(no_membrs)) %>%
arrange(min_membrs)
`summarise()` has grouped output by 'village'. You can override using the `.groups` argument.
# A tibble: 6 x 4
# Groups: village [3]
village memb_assoc mean_no_membrs min_membrs
<chr> <chr> <dbl> <dbl>
1 Chirodzo yes 7.82 2
2 Ruaca no 7.18 2
3 God no 7.13 3
4 Chirodzo no 8.06 4
5 God yes 8 5
6 Ruaca yes 9.5 5
To sort in descending order, we need to add the desc() function. If we want to
sort the results by decreasing order of minimum household size:
interviews %>%
filter(!is.na(memb_assoc)) %>%
group_by(village, memb_assoc) %>%
summarize(mean_no_membrs = mean(no_membrs),
min_membrs = min(no_membrs)) %>%
arrange(desc(min_membrs))
`summarise()` has grouped output by 'village'. You can override using the `.groups` argument.
# A tibble: 6 x 4
# Groups: village [3]
village memb_assoc mean_no_membrs min_membrs
<chr> <chr> <dbl> <dbl>
1 God yes 8 5
2 Ruaca yes 9.5 5
3 Chirodzo no 8.06 4
4 God no 7.13 3
5 Chirodzo yes 7.82 2
6 Ruaca no 7.18 2
Counting
When working with data, we often want to know the number of observations found
for each factor or combination of factors. For this task, dplyr provides
count(). For example, if we wanted to count the number of rows of data for
each village, we would do:
interviews %>%
count(village)
# A tibble: 3 x 2
village n
<chr> <int>
1 Chirodzo 39
2 God 43
3 Ruaca 49
For convenience, count() provides the sort argument to get results in
decreasing order:
interviews %>%
count(village, sort = TRUE)
# A tibble: 3 x 2
village n
<chr> <int>
1 Ruaca 49
2 God 43
3 Chirodzo 39
Exercise
How many households in the survey have an average of two meals per day? Three meals per day? Are there any other numbers of meals represented?
Solution
interviews %>% count(no_meals)# A tibble: 2 x 2 no_meals n <dbl> <int> 1 2 52 2 3 79Use
group_by()andsummarize()to find the mean, min, and max number of household members for each village. Also add the number of observations (hint: see?n).Solution
interviews %>% group_by(village) %>% summarize( mean_no_membrs = mean(no_membrs), min_no_membrs = min(no_membrs), max_no_membrs = max(no_membrs), n = n() )# A tibble: 3 x 5 village mean_no_membrs min_no_membrs max_no_membrs n <chr> <dbl> <dbl> <dbl> <int> 1 Chirodzo 7.08 2 12 39 2 God 6.86 3 15 43 3 Ruaca 7.57 2 19 49What was the largest household interviewed in each month?
Solution
# if not already included, add month, year, and day columns library(lubridate) # load lubridate if not already loadedAttaching package: 'lubridate'The following objects are masked from 'package:base': date, intersect, setdiff, unioninterviews %>% mutate(month = month(interview_date), day = day(interview_date), year = year(interview_date)) %>% group_by(year, month) %>% summarize(max_no_membrs = max(no_membrs))`summarise()` has grouped output by 'year'. You can override using the `.groups` argument.# A tibble: 5 x 3 # Groups: year [2] year month max_no_membrs <dbl> <dbl> <dbl> 1 2016 11 19 2 2016 12 12 3 2017 4 17 4 2017 5 15 5 2017 6 15
Reshaping with pivot_wider() and pivot_longer()
There are essentially three rules that define a “tidy” dataset:
- Each variable has its own column
- Each observation has its own row
- Each value must have its own cell
In this section we will explore how these rules are linked to the different
data formats researchers are often interested in: “wide” and “long”. This
tutorial will help you efficiently transform your data shape regardless of
original format. First we will explore qualities of the interviews data and
how they relate to these different types of data formats.
Long and wide data formats
In the interviews data, each row contains the values of variables associated
with each record collected (each interview in the villages), where it is stated
that the the key_ID was “added to provide a unique Id for each observation”
and the instance_ID “does this as well but it is not as convenient to use.”
However, with some inspection, we notice that there are more than one row in the
dataset with the same key_ID (as seen below). However, the instanceIDs
associated with these duplicate key_IDs are not the same. Thus, we should
think of instanceID as the unique identifier for observations!
interviews %>%
select(key_ID, village, interview_date, instanceID)
# A tibble: 131 x 4
key_ID village interview_date instanceID
<dbl> <chr> <dttm> <chr>
1 1 God 2016-11-17 00:00:00 uuid:ec241f2c-0609-46ed-b5e8-fe575f6cefef
2 1 God 2016-11-17 00:00:00 uuid:099de9c9-3e5e-427b-8452-26250e840d6e
3 3 God 2016-11-17 00:00:00 uuid:193d7daf-9582-409b-bf09-027dd36f9007
4 4 God 2016-11-17 00:00:00 uuid:148d1105-778a-4755-aa71-281eadd4a973
5 5 God 2016-11-17 00:00:00 uuid:2c867811-9696-4966-9866-f35c3e97d02d
6 6 God 2016-11-17 00:00:00 uuid:daa56c91-c8e3-44c3-a663-af6a49a2ca70
7 7 God 2016-11-17 00:00:00 uuid:ae20a58d-56f4-43d7-bafa-e7963d850844
8 8 Chirodzo 2016-11-16 00:00:00 uuid:d6cee930-7be1-4fd9-88c0-82a08f90fb5a
9 9 Chirodzo 2016-11-16 00:00:00 uuid:846103d2-b1db-4055-b502-9cd510bb7b37
10 10 Chirodzo 2016-12-16 00:00:00 uuid:8f4e49bc-da81-4356-ae34-e0d794a23721
# … with 121 more rows
As seen in the code below, for each interview date in each village no
instanceIDs are the same. Thus, this format is what is called a “long” data
format, where each observation occupies only one row in the dataframe.
interviews %>%
filter(village == "Chirodzo") %>%
select(key_ID, village, interview_date, instanceID) %>%
sample_n(size = 10)
# A tibble: 10 x 4
key_ID village interview_date instanceID
<dbl> <chr> <dttm> <chr>
1 65 Chirodzo 2016-11-16 00:00:00 uuid:143f7478-0126-4fbc-86e0-5d324339206b
2 67 Chirodzo 2016-11-16 00:00:00 uuid:6c15d667-2860-47e3-a5e7-7f679271e419
3 192 Chirodzo 2017-06-03 00:00:00 uuid:f94409a6-e461-4e4c-a6fb-0072d3d58b00
4 21 Chirodzo 2016-11-16 00:00:00 uuid:cc7f75c5-d13e-43f3-97e5-4f4c03cb4b12
5 50 Chirodzo 2016-11-16 00:00:00 uuid:4267c33c-53a7-46d9-8bd6-b96f58a4f92c
6 8 Chirodzo 2016-11-16 00:00:00 uuid:d6cee930-7be1-4fd9-88c0-82a08f90fb5a
7 46 Chirodzo 2016-11-17 00:00:00 uuid:35f297e0-aa5d-4149-9b7b-4965004cfc37
8 45 Chirodzo 2016-11-17 00:00:00 uuid:e3554d22-35b1-4fb9-b386-dd5866ad5792
9 69 Chirodzo 2016-11-16 00:00:00 uuid:f86933a5-12b8-4427-b821-43c5b039401d
10 36 Chirodzo 2016-11-17 00:00:00 uuid:c90eade0-1148-4a12-8c0e-6387a36f45b1
We notice that the layout or format of the interviews data is in a format that
adheres to rules 1-3, where
- each column is a variable
- each row is an observation
- each value has its own cell
This is called a “long” data format. But, we notice that each column represents a different variable. In the “longest” data format there would only be three columns, one for the id variable, one for the observed variable, and one for the observed value (of that variable). This data format is quite unsightly and difficult to work with, so you will rarely see it in use.
Alternatively, in a “wide” data format we see modifications to rule 1, where each column no longer represents a single variable. Instead, columns can represent different levels/values of a variable. For instance, in some data you encounter the researchers may have chosen for every survey date to be a different column.
These may sound like dramatically different data layouts, but there are some tools that make transitions between these layouts much simpler than you might think! The gif below shows how these two formats relate to each other, and gives you an idea of how we can use R to shift from one format to the other.
 Long and wide dataframe layouts mainly affect readability. You may find that
visually you may prefer the “wide” format, since you can see more of the data on
the screen. However, all of the R functions we have used thus far expect for
your data to be in a “long” data format. This is because the long format is more
machine readable and is closer to the formatting of databases.
Long and wide dataframe layouts mainly affect readability. You may find that
visually you may prefer the “wide” format, since you can see more of the data on
the screen. However, all of the R functions we have used thus far expect for
your data to be in a “long” data format. This is because the long format is more
machine readable and is closer to the formatting of databases.
Questions which warrant different data formats
In interviews, each row contains the values of variables associated with each record (the unit), values such as the village of the respondent, the number of household members, or the type of wall their house had. This format allows for us to make comparisons across individual surveys, but what if we wanted to look at differences in households grouped by different types of housing construction materials?
To facilitate this comparison we would need to create a new table where each row
(the unit) was comprised of values of variables associated with housing material
(e.g. the respondent_wall_type). In practical terms this means the values of
the wall construction materials in respondent_wall_type (e.g. muddaub,
burntbricks, cement, sunbricks) would become the names of column variables and
the cells would contain values of TRUE or FALSE, for whether that house had
a wall made of that material.
Once we we’ve created this new table, we can explore the relationship within and between villages. The key point here is that we are still following a tidy data structure, but we have reshaped the data according to the observations of interest.
Alternatively, if the interview dates were spread across multiple columns, and we were interested in visualizing, within each village, how irrigation conflicts have changed over time. This would require for the interview date to be included in a single column rather than spread across multiple columns. Thus, we would need to transform the column names into values of a variable.
We can do both these of transformations with two tidyr functions,
pivot_wider() and pivot_longer().
Pivoting wider
pivot_wider() takes three principal arguments:
- the data
- the names_from column variable whose values will become new column names.
- the values_from column variable whose values will fill the new column variables.
Further arguments include values_fill which, if set, fills in missing values
with the value provided.
Let’s use pivot_wider() to transform interviews to create new columns for each
type of wall construction material. We will make use of the pipe operator as
have done before. Because both the names_from and values_from parameters
must come from column values, we will create a dummy column (we’ll name it
wall_type_logical) to hold the value TRUE, which we will then place into the
appropriate column that corresponds to the wall construction material for that
respondent. When using mutate() if you give a single value, it will be used
for all observations in the dataset.
For each row in our newly pivoted table, only one of the newly created wall type
columns will have a value of TRUE, since each house can only be made of one
wall type. The default value that pivot_wider uses to fill the other wall
types is NA.

If instead of the default value being NA, we wanted these values to be FALSE,
we can insert a default value into the values_fill argument. By including
values_fill = list(wall_type_logical = FALSE) inside pivot_wider(), we can
fill the remainder of the wall type columns for that row with the value FALSE.
interviews_wide <- interviews %>%
mutate(wall_type_logical = TRUE) %>%
pivot_wider(names_from = respondent_wall_type,
values_from = wall_type_logical,
values_fill = list(wall_type_logical = FALSE))
View the interviews_wide dataframe and notice that there is no longer a
column titled respondent_wall_type. This is because there is a default
parameter in pivot_wider() that drops the original column. The values that
were in that column have now become columns named muddaub, burntbricks,
sunbricks, and cement. You can use dim(interviews) and
dim(interviews_wide) to see how the number of columns has changed between
the two datasets.
Pivoting longer
The opposing situation could occur if we had been provided with data in the form
of interviews_wide, where the building materials are column names, but we
wish to treat them as values of a respondent_wall_type variable instead.
In this situation we are gathering these columns turning them into a pair of new variables. One variable includes the column names as values, and the other variable contains the values in each cell previously associated with the column names. We will do this in two steps to make this process a bit clearer.
pivot_longer() takes four principal arguments:
- the data
- cols are the names of the columns we use to fill the a new values variable (or to drop).
- the names_to column variable we wish to create from the cols provided.
- the values_to column variable we wish to create and fill with values associated with the cols provided.
To recreate our original dataframe, we will use the following:
- the data -
interviews_wide - a list of cols (columns) that are to be reshaped; these can be specified
using a
:if the columns to be reshaped are in one area of the dataframe, or with a vector (c()) command if the columns are spread throughout the dataframe. - the names_to column will be a character string of the name the column these columns will be collapsed into (“respondent_wall_type”).
- the values_to column will be a character string of the name of the
column the values of the collapsed columns will be inserted into
(“wall_type_logical”). This column will be populated with values of
TRUEorFALSE.
interviews_long <- interviews_wide %>%
pivot_longer(cols = burntbricks:sunbricks,
names_to = "respondent_wall_type",
values_to = "wall_type_logical")

This creates a dataframe with 262 rows (4 rows per interview respondent). The four rows for each respondent differ only in the value of the “respondent_wall_type” and “wall_type_logical” columns. View the data to see what this looks like.
Only one row for each interview respondent is informative–we know that if the
house walls are made of “sunbrick” they aren’t made of any other the other
materials. Therefore, it would make sense to filter our dataset to only keep
values where wall_type_logical is TRUE. Because wall_type_logical is
already either TRUE or FALSE, when passing the column name to filter(),
it will automatically already only keep rows where this column has the value
TRUE. We can then remove the wall_type_logical column.
We do all of these steps together in the next chunk of code:
interviews_long <- interviews_wide %>%
pivot_longer(cols = c(burntbricks, cement, muddaub, sunbricks),
names_to = "respondent_wall_type",
values_to = "wall_type_logical") %>%
filter(wall_type_logical) %>%
select(-wall_type_logical)
View both interviews_long and interviews_wide and compare their structure.
Applying pivot_wider() to clean our data
Now that we’ve learned about pivot_longer() and pivot_wider() we’re going to
put these functions to use to fix a problem with the way that our data is
structured. In the spreadsheets lesson, we learned that it’s best practice to
have only a single piece of information in each cell of your spreadsheet. In
this dataset, we have several columns which contain multiple pieces of
information. For example, the items_owned column contains information about
whether our respondents owned a fridge, a television, etc. To make this data
easier to analyze, we will split this column and create a new column for each
item. Each cell in that column will either be TRUE or FALSE and will
indicate whether that interview respondent owned that item (similar to what
we did previously with wall_type).
interviews_items_owned <- interviews %>%
separate_rows(items_owned, sep = ";") %>%
replace_na(list(items_owned = "no_listed_items")) %>%
mutate(items_owned_logical = TRUE) %>%
pivot_wider(names_from = items_owned,
values_from = items_owned_logical,
values_fill = list(items_owned_logical = FALSE))
nrow(interviews_items_owned)
[1] 131
There are a couple of new concepts in this code chunk, so let’s walk through it
line by line. First we create a new object (interviews_items_owned) based on
the interviews dataframe.
interviews_items_owned <- interviews %>%
Then we use the new function separate_rows() from the tidyr package to
separate the values of items_owned based on the presence of semi-colons (;).
The values of this variable were multiple items separated by semi-colons, so
this action creates a row for each item listed in a household’s possession.
Thus, we end up with a long format version of the dataset, with multiple rows
for each respondent. For example, if a respondent has a television and a solar
panel, that respondent will now have two rows, one with “television” and the
other with “solar panel” in the items_owned column.
separate_rows(items_owned, sep = ";") %>%
You may notice that one of the columns is called ´NA´. This is because some
of the respondents did not own any of the items that was in the interviewer’s
list. We can use the replace_na() function to change these NA values to
something more meaningful. The replace_na() function expects for you to give
it a list() of columns that you would like to replace the NA values in,
and the value that you would like to replace the NAs. This ends up looking
like this:
replace_na(list(items_owned = "no_listed_items")) %>%
Next, we create a new variable named items_owned_logical, which has one value
(TRUE) for every row. This makes sense, since each item in every row was owned
by that household. We are constructing this variable so that when spread the
items_owned across multiple columns, we can fill the values of those columns
with logical values describing whether the household did (TRUE) or didn’t
(FALSE) own that particular item.
mutate(items_owned_logical = TRUE) %>%
Lastly, we use pivot_wider() to switch from long format to wide format. This
creates a new column for each of the unique values in the items_owned column,
and fills those columns with the values of items_owned_logical. We also
declare that for items that are missing, we want to fill those cells with the
value of FALSE instead of NA.
pivot_wider(names_from = items_owned,
values_from = items_owned_logical,
values_fill = list(items_owned_logical = FALSE))
View the interviews_items_owned dataframe. It should have
131 rows (the same number of rows you had originally), but
extra columns for each item. How many columns were added?
This format of the data allows us to do interesting things, like make a table showing the number of respondents in each village who owned a particular item:
interviews_items_owned %>%
filter(bicycle) %>%
group_by(village) %>%
count(bicycle)
# A tibble: 3 x 3
# Groups: village [3]
village bicycle n
<chr> <lgl> <int>
1 Chirodzo TRUE 17
2 God TRUE 23
3 Ruaca TRUE 20
Or below we calculate the average number of items from the list owned by
respondents in each village. This code uses the rowSums() function to count
the number of TRUE values in the bicycle to car columns for each row,
hence its name. We then group the data by villages and caluculate the mean
number of items, so each average is grouped by village.
interviews_items_owned %>%
mutate(number_items = rowSums(select(., bicycle:car))) %>%
group_by(village) %>%
summarize(mean_items = mean(number_items))
# A tibble: 3 x 2
village mean_items
<chr> <dbl>
1 Chirodzo 4.62
2 God 4.07
3 Ruaca 5.63
Exercise
- Create a new dataframe (named
interviews_months_lack_food) that has one column for each month and recordsTRUEorFALSEfor whether each interview respondent was lacking food in that month.Solution
interviews_months_lack_food <- interviews %>% separate_rows(months_lack_food, sep = ";") %>% mutate(months_lack_food_logical = TRUE) %>% pivot_wider(names_from = months_lack_food, values_from = months_lack_food_logical, values_fill = list(months_lack_food_logical = FALSE))
- How many months (on average) were respondents without food if they did belong to an irrigation association? What about if they didn’t?
Solution
interviews_months_lack_food %>% mutate(number_months = rowSums(select(., Jan:May))) %>% group_by(memb_assoc) %>% summarize(mean_months = mean(number_months))# A tibble: 3 x 2 memb_assoc mean_months <chr> <dbl> 1 no 2 2 yes 2.30 3 <NA> 2.82
Exporting data
Now that you have learned how to use dplyr to extract information from
or summarize your raw data, you may want to export these new data sets to share
them with your collaborators or for archival.
Similar to the read_csv() function used for reading CSV files into R, there is
a write_csv() function that generates CSV files from dataframes.
Before using write_csv(), we are going to create a new folder, data_output,
in our working directory that will store this generated dataset. We don’t want
to write generated datasets in the same directory as our raw data. It’s good
practice to keep them separate. The data folder should only contain the raw,
unaltered data, and should be left alone to make sure we don’t delete or modify
it. In contrast, our script will generate the contents of the data_output
directory, so even if the files it contains are deleted, we can always
re-generate them.
In preparation for our next lesson on plotting, we are going to create a version
of the dataset where each of the columns includes only one data value. To do
this, we will use pivot_wider to expand the months_lack_food and
items_owned columns. We will also create a couple of summary columns.
interviews_plotting <- interviews %>%
## pivot wider by items_owned
separate_rows(items_owned, sep = ";") %>%
## if there were no items listed, changing NA to no_listed_items
replace_na(list(items_owned = "no_listed_items")) %>%
mutate(items_owned_logical = TRUE) %>%
pivot_wider(names_from = items_owned,
values_from = items_owned_logical,
values_fill = list(items_owned_logical = FALSE)) %>%
## pivot wider by months_lack_food
separate_rows(months_lack_food, sep = ";") %>%
mutate(months_lack_food_logical = TRUE) %>%
pivot_wider(names_from = months_lack_food,
values_from = months_lack_food_logical,
values_fill = list(months_lack_food_logical = FALSE)) %>%
## add some summary columns
mutate(number_months_lack_food = rowSums(select(., Jan:May))) %>%
mutate(number_items = rowSums(select(., bicycle:car)))
Now we can save this dataframe to our data_output directory.
write_csv (interviews_plotting, file = "data_output/interviews_plotting.csv")
Key Points
Use the
dplyrpackage to manipulate dataframes.Use
select()to choose variables from a dataframe.Use
filter()to choose data based on values.Use
group_by()andsummarize()to work with subsets of data.Use
mutate()to create new variables.Use the
tidyrpackage to change the layout of dataframes.Use
pivot_wider()to go from long to wide format.Use
pivot_longer()to go from wide to long format.
Creating Publication-Quality Graphics with ggplot2
Overview
Teaching: 60 min
Exercises: 20 minQuestions
How can I create publication-quality graphics in R?
Objectives
To be able to use ggplot2 to generate publication quality graphics.
To apply geometry, aesthetic, and statistics layers to a ggplot plot.
To manipulate the aesthetics of a plot using different colors, shapes, and lines.
To improve data visualization through transforming scales and paneling by group.
To save a plot created with ggplot to disk.
Plotting our data is one of the best ways to quickly explore it and the various relationships between variables.
There are three main plotting systems in R, the base plotting system, the lattice package, and the ggplot2 package.
Today we’ll be learning about the ggplot2 package, because it is the most effective for creating publication quality graphics.
ggplot2 is built on the grammar of graphics, the idea that any plot can be expressed from the same set of components: a data set, a coordinate system, and a set of geoms – the visual representation of data points.
The key to understanding ggplot2 is thinking about a figure in layers. This idea may be familiar to you if you have used image editing programs like Photoshop, Illustrator, or Inkscape.
Let’s start off with an example:
library("ggplot2")
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) +
geom_point()

So the first thing we do is call the ggplot function. This function lets R
know that we’re creating a new plot, and any of the arguments we give the
ggplot function are the global options for the plot: they apply to all
layers on the plot.
We’ve passed in two arguments to ggplot. First, we tell ggplot what data we
want to show on our figure, in this example the gapminder data we read in
earlier. For the second argument, we passed in the aes function, which
tells ggplot how variables in the data map to aesthetic properties of
the figure, in this case the x and y locations. Here we told ggplot we
want to plot the “gdpPercap” column of the gapminder data frame on the x-axis, and
the “lifeExp” column on the y-axis. Notice that we didn’t need to explicitly
pass aes these columns (e.g. x = gapminder[, "gdpPercap"]), this is because
ggplot is smart enough to know to look in the data for that column!
By itself, the call to ggplot isn’t enough to draw a figure:
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp))

We need to tell ggplot how we want to visually represent the data, which we
do by adding a new geom layer. In our example, we used geom_point, which
tells ggplot we want to visually represent the relationship between x and
y as a scatterplot of points:
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) +
geom_point()

Challenge 1
Modify the example so that the figure shows how life expectancy has changed over time:
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) + geom_point()Hint: the gapminder dataset has a column called “year”, which should appear on the x-axis.
Solution to challenge 1
Here is one possible solution:
ggplot(data = gapminder, mapping = aes(x = year, y = lifeExp)) + geom_point()

Challenge 2
In the previous examples and challenge we’ve used the
aesfunction to tell the scatterplot geom about the x and y locations of each point. Another aesthetic property we can modify is the point color. Modify the code from the previous challenge to color the points by the “continent” column. What trends do you see in the data? Are they what you expected?Solution to challenge 2
The solution presented below adds
color=continentto the call of theaesfunction. The general trend seems to indicate an increased life expectancy over the years. On continents with stronger economies we find a longer life expectancy.ggplot(data = gapminder, mapping = aes(x = year, y = lifeExp, color=continent)) + geom_point()

Layers
Using a scatterplot probably isn’t the best for visualizing change over time.
Instead, let’s tell ggplot to visualize the data as a line plot:
ggplot(data = gapminder, mapping = aes(x=year, y=lifeExp, by=country, color=continent)) +
geom_line()

Instead of adding a geom_point layer, we’ve added a geom_line layer. We’ve
added the by aesthetic, which tells ggplot to draw a line for each
country.
But what if we want to visualize both lines and points on the plot? We can add another layer to the plot:
ggplot(data = gapminder, mapping = aes(x=year, y=lifeExp, by=country, color=continent)) +
geom_line() + geom_point()

It’s important to note that each layer is drawn on top of the previous layer. In this example, the points have been drawn on top of the lines. Here’s a demonstration:
ggplot(data = gapminder, mapping = aes(x=year, y=lifeExp, by=country)) +
geom_line(mapping = aes(color=continent)) + geom_point()

In this example, the aesthetic mapping of color has been moved from the
global plot options in ggplot to the geom_line layer so it no longer applies
to the points. Now we can clearly see that the points are drawn on top of the
lines.
Tip: Setting an aesthetic to a value instead of a mapping
So far, we’ve seen how to use an aesthetic (such as color) as a mapping to a variable in the data. For example, when we use
geom_line(mapping = aes(color=continent)), ggplot will give a different color to each continent. But what if we want to change the colour of all lines to blue? You may think thatgeom_line(mapping = aes(color="blue"))should work, but it doesn’t. Since we don’t want to create a mapping to a specific variable, we can move the color specification outside of theaes()function, like this:geom_line(color="blue").
Challenge 3
Switch the order of the point and line layers from the previous example. What happened?
Solution to challenge 3
The lines now get drawn over the points!
ggplot(data = gapminder, mapping = aes(x=year, y=lifeExp, by=country)) + geom_point() + geom_line(mapping = aes(color=continent))

Transformations and statistics
ggplot2 also makes it easy to overlay statistical models over the data. To demonstrate we’ll go back to our first example:
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) +
geom_point()

Currently it’s hard to see the relationship between the points due to some strong outliers in GDP per capita. We can change the scale of units on the x axis using the scale functions. These control the mapping between the data values and visual values of an aesthetic. We can also modify the transparency of the points, using the alpha function, which is especially helpful when you have a large amount of data which is very clustered.
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) +
geom_point(alpha = 0.5) + scale_x_log10()

The scale_x_log10 function applied a transformation to the coordinate system of the plot, so that each multiple of 10 is evenly spaced from left to right. For example, a GDP per capita of 1,000 is the same horizontal distance away from a value of 10,000 as the 10,000 value is from 100,000. This helps to visualize the spread of the data along the x-axis.
Tip Reminder: Setting an aesthetic to a value instead of a mapping
Notice that we used
geom_point(alpha = 0.5). As the previous tip mentioned, using a setting outside of theaes()function will cause this value to be used for all points, which is what we want in this case. But just like any other aesthetic setting, alpha can also be mapped to a variable in the data. For example, we can give a different transparency to each continent withgeom_point(mapping = aes(alpha = continent)).
We can fit a simple relationship to the data by adding another layer,
geom_smooth:
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) +
geom_point() + scale_x_log10() + geom_smooth(method="lm")
`geom_smooth()` using formula 'y ~ x'

We can make the line thicker by setting the size aesthetic in the
geom_smooth layer:
ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) +
geom_point() + scale_x_log10() + geom_smooth(method="lm", size=1.5)
`geom_smooth()` using formula 'y ~ x'

There are two ways an aesthetic can be specified. Here we set the size
aesthetic by passing it as an argument to geom_smooth. Previously in the
lesson we’ve used the aes function to define a mapping between data
variables and their visual representation.
Challenge 4a
Modify the color and size of the points on the point layer in the previous example.
Hint: do not use the
aesfunction.Solution to challenge 4a
Here a possible solution: Notice that the
colorargument is supplied outside of theaes()function. This means that it applies to all data points on the graph and is not related to a specific variable.ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp)) + geom_point(size=3, color="orange") + scale_x_log10() + geom_smooth(method="lm", size=1.5)`geom_smooth()` using formula 'y ~ x'

Challenge 4b
Modify your solution to Challenge 4a so that the points are now a different shape and are colored by continent with new trendlines. Hint: The color argument can be used inside the aesthetic.
Solution to challenge 4b
Here is a possible solution: Notice that supplying the
colorargument inside theaes()functions enables you to connect it to a certain variable. Theshapeargument, as you can see, modifies all data points the same way (it is outside theaes()call) while thecolorargument which is placed inside theaes()call modifies a point’s color based on its continent value.ggplot(data = gapminder, mapping = aes(x = gdpPercap, y = lifeExp, color = continent)) + geom_point(size=3, shape=17) + scale_x_log10() + geom_smooth(method="lm", size=1.5)`geom_smooth()` using formula 'y ~ x'

Multi-panel figures
Earlier we visualized the change in life expectancy over time across all countries in one plot. Alternatively, we can split this out over multiple panels by adding a layer of facet panels.
Tip
We start by making a subset of data including only countries located in the Americas. This includes 25 countries, which will begin to clutter the figure. Note that we apply a “theme” definition to rotate the x-axis labels to maintain readability. Nearly everything in ggplot2 is customizable.
americas <- gapminder[gapminder$continent == "Americas",]
ggplot(data = americas, mapping = aes(x = year, y = lifeExp)) +
geom_line() +
facet_wrap( ~ country) +
theme(axis.text.x = element_text(angle = 45))

The facet_wrap layer took a “formula” as its argument, denoted by the tilde
(~). This tells R to draw a panel for each unique value in the country column
of the gapminder dataset.
Modifying text
To clean this figure up for a publication we need to change some of the text elements. The x-axis is too cluttered, and the y axis should read “Life expectancy”, rather than the column name in the data frame.
We can do this by adding a couple of different layers. The theme layer
controls the axis text, and overall text size. Labels for the axes, plot
title and any legend can be set using the labs function. Legend titles
are set using the same names we used in the aes specification. Thus below
the color legend title is set using color = "Continent", while the title
of a fill legend would be set using fill = "MyTitle".
ggplot(data = americas, mapping = aes(x = year, y = lifeExp, color=continent)) +
geom_line() + facet_wrap( ~ country) +
labs(
x = "Year", # x axis title
y = "Life expectancy", # y axis title
title = "Figure 1", # main title of figure
color = "Continent" # title of legend
) +
theme(axis.text.x = element_text(angle = 90, hjust = 1))

Exporting the plot
The ggsave() function allows you to export a plot created with ggplot. You can specify the dimension and resolution of your plot by adjusting the appropriate arguments (width, height and dpi) to create high quality graphics for publication. In order to save the plot from above, we first assign it to a variable lifeExp_plot, then tell ggsave to save that plot in png format to a directory called results. (Make sure you have a results/ folder in your working directory.)
lifeExp_plot <- ggplot(data = americas, mapping = aes(x = year, y = lifeExp, color=continent)) +
geom_line() + facet_wrap( ~ country) +
labs(
x = "Year", # x axis title
y = "Life expectancy", # y axis title
title = "Figure 1", # main title of figure
color = "Continent" # title of legend
) +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
ggsave(filename = "results/lifeExp.png", plot = lifeExp_plot, width = 12, height = 10, dpi = 300, units = "cm")
There are two nice things about ggsave. First, it defaults to the last plot, so if you omit the plot argument it will automatically save the last plot you created with ggplot. Secondly, it tries to determine the format you want to save your plot in from the file extension you provide for the filename (for example .png or .pdf). If you need to, you can specify the format explicitly in the device argument.
This is a taste of what you can do with ggplot2. RStudio provides a really useful cheat sheet of the different layers available, and more extensive documentation is available on the ggplot2 website. Finally, if you have no idea how to change something, a quick Google search will usually send you to a relevant question and answer on Stack Overflow with reusable code to modify!
Challenge 5
Generate boxplots to compare life expectancy between the different continents during the available years.
Advanced:
- Rename y axis as Life Expectancy.
- Remove x axis labels.
Solution to Challenge 5
Here a possible solution:
xlab()andylab()set labels for the x and y axes, respectively The axis title, text and ticks are attributes of the theme and must be modified within atheme()call.ggplot(data = gapminder, mapping = aes(x = continent, y = lifeExp, fill = continent)) + geom_boxplot() + facet_wrap(~year) + ylab("Life Expectancy") + theme(axis.title.x=element_blank(), axis.text.x = element_blank(), axis.ticks.x = element_blank())

Key Points
Use
ggplot2to create plots.Think about graphics in layers: aesthetics, geometry, statistics, scale transformation, and grouping.
Producing Reports With knitr
Overview
Teaching: 60 min
Exercises: 15 minQuestions
How can I integrate software and reports?
Objectives
Understand the value of writing reproducible reports
Learn how to recognise and compile the basic components of an R Markdown file
Become familiar with R code chunks, and understand their purpose, structure and options
Demonstrate the use of inline chunks for weaving R outputs into text blocks, for example when discussing the results of some calculations
Be aware of alternative output formats to which an R Markdown file can be exported
Data analysis reports
Data analysts tend to write a lot of reports, describing their analyses and results, for their collaborators or to document their work for future reference.
Many new users begin by first writing a single R script containing all of their work, and then share the analysis by emailing the script and various graphs as attachments. But this can be cumbersome, requiring a lengthy discussion to explain which attachment was which result.
Writing formal reports with Word or LaTeX can simplify this process by incorporating both the analysis report and output graphs into a single document. But tweaking formatting to make figures look correct and fixing obnoxious page breaks can be tedious and lead to a lengthly “whack-a-mole” game of fixing new mistakes resulting from a single formatting change.
Creating a web page (as an html file) using R Markdown makes things easier. The report can be one long stream, so tall figures that wouldn’t ordinarily fit on one page can be kept at full size and easier to read, since the reader can simply keep scrolling. Additionally, the formatting of and R Markdown document is simple and easy to modify, allowing you to spend more time on your analyses instead of writing reports.
Literate programming
Ideally, such analysis reports are reproducible documents: If an error is discovered, or if some additional subjects are added to the data, you can just re-compile the report and get the new or corrected results rather than having to reconstruct figures, paste them into a Word document, and hand-edit various detailed results.
The key R package here is knitr. It allows you
to create a document that is a mixture of text and chunks of
code. When the document is processed by knitr, chunks of code will
be executed, and graphs or other results will be inserted into the final document.
This sort of idea has been called “literate programming”.
knitr allows you to mix basically any type of text with code from different programming languages, but we recommend that you use R Markdown, which mixes Markdown
with R. Markdown is a light-weight mark-up language for creating web
pages.
Creating an R Markdown file
Within RStudio, click File → New File → R Markdown and you’ll get a dialog box like this:
You can stick with the default (HTML output), but give it a title.
Basic components of R Markdown
The initial chunk of text (header) contains instructions for R to specify what kind of document will be created, and the options chosen. You can use the header to give your document a title, author, date, and tell it what type of output you want to produce. In this case, we’re creating an html document.
---
title: "Initial R Markdown document"
author: "Karl Broman"
date: "April 23, 2015"
output: html_document
---
You can delete any of those fields if you don’t want them included. The double-quotes aren’t strictly necessary in this case. They’re mostly needed if you want to include a colon in the title.
RStudio creates the document with some example text to get you started. Note below that there are chunks like
```{r}
summary(cars)
```
These are chunks of R code that will be executed by knitr and replaced
by their results. More on this later.
Markdown
Markdown is a system for writing web pages by marking up the text much as you would in an email rather than writing html code. The marked-up text gets converted to html, replacing the marks with the proper html code.
For now, let’s delete all of the stuff that’s there and write a bit of markdown.
You make things bold using two asterisks, like this: **bold**,
and you make things italics by using underscores, like this:
_italics_.
You can make a bulleted list by writing a list with hyphens or asterisks, like this:
* bold with double-asterisks
* italics with underscores
* code-type font with backticks
or like this:
- bold with double-asterisks
- italics with underscores
- code-type font with backticks
Each will appear as:
- bold with double-asterisks
- italics with underscores
- code-type font with backticks
You can use whatever method you prefer, but be consistent. This maintains the readability of your code.
You can make a numbered list by just using numbers. You can even use the same number over and over if you want:
1. bold with double-asterisks
1. italics with underscores
1. code-type font with backticks
This will appear as:
- bold with double-asterisks
- italics with underscores
- code-type font with backticks
You can make section headers of different sizes by initiating a line
with some number of # symbols:
# Title
## Main section
### Sub-section
#### Sub-sub section
You compile the R Markdown document to an html webpage by clicking the “Knit” button in the upper-left.
Challenge 1
Create a new R Markdown document. Delete all of the R code chunks and write a bit of Markdown (some sections, some italicized text, and an itemized list).
Convert the document to a webpage.
Solution to Challenge 1
In RStudio, select File > New file > R Markdown…
Delete the placeholder text and add the following:
# Introduction ## Background on Data This report uses the *gapminder* dataset, which has columns that include: * country * continent * year * lifeExp * pop * gdpPercap ## Background on MethodsThen click the ‘Knit’ button on the toolbar to generate an html document (webpage).
A bit more Markdown
You can make a hyperlink like this:
[text to show](http://the-web-page.com).
You can include an image file like this: 
You can do subscripts (e.g., F~2~) with F~2~ and superscripts (e.g.,
F^2^) with F^2^.
If you know how to write equations in
LaTeX, you can use $ $ and $$ $$ to insert math equations, like
$E = mc^2$ and
$$y = \mu + \sum_{i=1}^p \beta_i x_i + \epsilon$$
You can review Markdown syntax by navigating to the “Markdown Quick Reference” under the “Help” field in the toolbar at the top of RStudio.
R code chunks
The real power of Markdown comes from mixing markdown with chunks of code. This is R Markdown. When processed, the R code will be executed; if they produce figures, the figures will be inserted in the final document.
The main code chunks look like this:
```{r load_data}
gapminder <- read.csv("gapminder.csv")
```
That is, you place a chunk of R code between ```{r chunk_name}
and ```. You should give each chunk
a unique name, as they will help you to fix errors and, if any graphs are
produced, the file names are based on the name of the code chunk that
produced them. You can create code chunks quickly in RStudio using the shortcuts
Ctrl+Alt+I on Windows and Linux, or Cmd+Option+I on Mac.
Challenge 2
Add code chunks to:
- Load the ggplot2 package
- Read the gapminder data
- Create a plot
Solution to Challenge 2
```{r load-ggplot2} library("ggplot2") ``````{r read-gapminder-data} gapminder <- read.csv("gapminder.csv") ``````{r make-plot} plot(lifeExp ~ year, data = gapminder) ```
How things get compiled
When you press the “Knit” button, the R Markdown document is
processed by knitr and a plain Markdown
document is produced (as well as, potentially, a set of figure files): the R code is executed
and replaced by both the input and the output; if figures are
produced, links to those figures are included.
The Markdown and figure documents are then processed by the tool
pandoc, which converts the Markdown file into an
html file, with the figures embedded.

Chunk options
There are a variety of options to affect how the code chunks are treated. Here are some examples:
- Use
echo=FALSEto avoid having the code itself shown. - Use
results="hide"to avoid having any results printed. - Use
eval=FALSEto have the code shown but not evaluated. - Use
warning=FALSEandmessage=FALSEto hide any warnings or messages produced. - Use
fig.heightandfig.widthto control the size of the figures produced (in inches).
So you might write:
```{r load_libraries, echo=FALSE, message=FALSE}
library("dplyr")
library("ggplot2")
```
Often there will be particular options that you’ll want to use repeatedly; for this, you can set global chunk options, like so:
```{r global_options, echo=FALSE}
knitr::opts_chunk$set(fig.path="Figs/", message=FALSE, warning=FALSE,
echo=FALSE, results="hide", fig.width=11)
```
The fig.path option defines where the figures will be saved. The /
here is really important; without it, the figures would be saved in
the standard place but just with names that begin with Figs.
If you have multiple R Markdown files in a common directory, you might
want to use fig.path to define separate prefixes for the figure file
names, like fig.path="Figs/cleaning-" and fig.path="Figs/analysis-".
Challenge 3
Use chunk options to control the size of a figure and to hide the code.
Solution to Challenge 3
```{r echo = FALSE, fig.width = 3} plot(faithful) ```
You can review all of the R chunk options by navigating to
the “R Markdown Cheat Sheet” under the “Cheatsheets” section
of the “Help” field in the toolbar at the top of RStudio.
Inline R code
You can make every number in your report reproducible. Use
`r and ` for an in-line code chunk,
like so: `r round(some_value, 2)`. The code will be
executed and replaced with the value of the result.
Don’t let these in-line chunks get split across lines.
Perhaps precede the paragraph with a larger code chunk that does
calculations and defines variables, with include=FALSE for that larger
chunk (which is the same as echo=FALSE and results="hide").
Rounding can produce differences in output in such situations. You may want
2.0, but round(2.03, 1) will give just 2.
The
myround
function in the R/broman package handles
this.
Challenge 4
Try out a bit of in-line R code.
Solution to Challenge 4
Here’s some inline code to determine that 2 + 2 =
`r 2+2`.
Other output options
You can also convert R Markdown to a PDF or a Word document. Click the
little triangle next to the “Knit” button to get a drop-down
menu. Or you could put pdf_document or word_document in the initial header
of the file.
Tip: Creating PDF documents
Creating .pdf documents may require installation of some extra software. The R package
tinytexprovides some tools to help make this process easier for R users. Withtinytexinstalled, runtinytex::install_tinytex()to install the required software (you’ll only need to do this once) and then when you knit to pdftinytexwill automatically detect and install any additional LaTeX packages that are needed to produce the pdf document. Visit the tinytex website for more information.
Resources
- Knitr in a knutshell tutorial
- Dynamic Documents with R and knitr (book)
- R Markdown documentation
- R Markdown cheat sheet
- Getting started with R Markdown
- R Markdown: The Definitive Guide (book by Rstudio team)
- Reproducible Reporting
- The Ecosystem of R Markdown
- Introducing Bookdown
Key Points
Mix reporting written in R Markdown with software written in R.
Specify chunk options to control formatting.
Use
knitrto convert these documents into PDF and other formats.
Command-Line Programs
Overview
Teaching: 30 min
Exercises: 0 minQuestions
How do I write a command-line script?
How do I read in arguments from the command-line?
Objectives
Use the values of command-line arguments in a program.
Handle flags and files separately in a command-line program.
Read data from standard input in a program so that it can be used in a pipeline.
The R Console and other interactive tools like RStudio are great for prototyping code and exploring data, but sooner or later we will want to use our program in a pipeline or run it in a shell script to process thousands of data files. In order to do that, we need to make our programs work like other Unix command-line tools. For example, we may want a program that reads a data set and prints the average inflammation per patient:
$ Rscript readings.R --mean data/inflammation-01.csv
5.45
5.425
6.1
...
6.4
7.05
5.9
but we might also want to look at the minimum of the first four lines
$ head -4 data/inflammation-01.csv | Rscript readings.R --min
or the maximum inflammations in several files one after another:
$ Rscript readings.R --max data/inflammation-*.csv
Our overall requirements are:
- If no filename is given on the command line, read data from standard input.
- If one or more filenames are given, read data from them and report statistics for each file separately.
- Use the
--min,--mean, or--maxflag to determine what statistic to print.
To make this work, we need to know how to handle command-line arguments in a program, and how to get at standard input. We’ll tackle these questions in turn below.
Command-Line Arguments
Using the text editor of your choice, save the following line of code in a text file called session-info.R:
sessionInfo()
The function, sessionInfo, outputs the version of R you are running as well as the type of computer you are using (as well as the versions of the packages that have been loaded).
This is very useful information to include when asking others for help with your R code.
Now we can run the code in the file we created from the Unix Shell using Rscript:
Rscript session-info.R
R version 4.1.0 (2021-05-18)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.2 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] compiler_4.1.0
The Right Directory
If that did not work, you might have seen an error message indicating that the file
session-info.Rdoes not exist. Remember that you must be in the correct directory, the one in which you created your script file. You can determine which directory you are currently in usingpwdand change to a different directory usingcd. For a review, see this lesson.
Now let’s create another script that does something more interesting. Write the following lines in a file named print-args.R:
args <- commandArgs()
cat(args, sep = "\n")
The function commandArgs extracts all the command line arguments and returns them as a vector.
The function cat, similar to the cat of the Unix Shell, outputs the contents of the variable.
Since we did not specify a filename for writing, cat sends the output to standard output,
which we can then pipe to other Unix functions.
Because we set the argument sep to "\n", which is the symbol to start a new line, each element of the vector is printed on its own line.
Let’s see what happens when we run this program in the Unix Shell:
Rscript print-args.R
/opt/R/4.1.0/lib/R/bin/exec/R
--no-echo
--no-restore
--file=print-args.R
From this output, we learn that Rscript is just a convenience command for running R scripts.
The first argument in the vector is the path to the R executable.
The following are all command-line arguments that affect the behavior of R.
From the R help file:
--slave: Make R run as quietly as possible--no-restore: Don’t restore anything that was created during the R session--file: Run this file--args: Pass these arguments to the file being run
Thus running a file with Rscript is an easier way to run the following:
R --slave --no-restore --file=print-args.R --args
/opt/R/4.1.0/lib/R/bin/exec/R
--slave
--no-restore
--file=print-args.R
--args
If we run it with a few arguments, however:
Rscript print-args.R first second third
/opt/R/4.1.0/lib/R/bin/exec/R
--no-echo
--no-restore
--file=print-args.R
--args
first
second
third
then commandArgs adds each of those arguments to the vector it returns.
Since the first elements of the vector are always the same, we can tell commandArgs to only return the arguments that come after --args.
Let’s update print-args.R and save it as print-args-trailing.R:
args <- commandArgs(trailingOnly = TRUE)
cat(args, sep = "\n")
And then run print-args-trailing from the Unix Shell:
Rscript print-args-trailing.R first second third
first
second
third
Now commandArgs returns only the arguments that we listed after print-args-trailing.R.
With this in hand, let’s build a version of readings.R that always prints the per-patient (per-row) mean of a single data file.
The first step is to write a function that outlines our implementation, and a placeholder for the function that does the actual work.
By convention this function is usually called main, though we can call it whatever we want.
Write the following code in a file called readings-01.R:
main <- function() {
args <- commandArgs(trailingOnly = TRUE)
filename <- args[1]
dat <- read.csv(file = filename, header = FALSE)
mean_per_patient <- apply(dat, 1, mean)
cat(mean_per_patient, sep = "\n")
}
This function gets the name of the file to process from the first element returned by commandArgs.
Here’s a simple test to run from the Unix Shell:
Rscript readings-01.R data/inflammation-01.csv
There is no output because we have defined a function, but haven’t actually called it.
Let’s add a call to main and save it as readings-02.R:
main <- function() {
args <- commandArgs(trailingOnly = TRUE)
filename <- args[1]
dat <- read.csv(file = filename, header = FALSE)
mean_per_patient <- apply(dat, 1, mean)
cat(mean_per_patient, sep = "\n")
}
main()
Rscript readings-02.R data/inflammation-01.csv
5.45
5.425
6.1
5.9
5.55
6.225
5.975
6.65
6.625
6.525
6.775
5.8
6.225
5.75
5.225
6.3
6.55
5.7
5.85
6.55
5.775
5.825
6.175
6.1
5.8
6.425
6.05
6.025
6.175
6.55
6.175
6.35
6.725
6.125
7.075
5.725
5.925
6.15
6.075
5.75
5.975
5.725
6.3
5.9
6.75
5.925
7.225
6.15
5.95
6.275
5.7
6.1
6.825
5.975
6.725
5.7
6.25
6.4
7.05
5.9
A Simple Command-Line Program
Write a command-line program that does addition and subtraction of two numbers.
Hint: Everything argument read from the command-line is interpreted as a character string. You can convert from a string to a number using the function
as.numeric.Rscript arith.R 1 + 23Rscript arith.R 3 - 4-1Solution
cat arith.Rmain <- function() { # Performs addition or subtraction from the command line. # # Takes three arguments: # The first and third are the numbers. # The second is either + for addition or - for subtraction. # # Ex. usage: # Rscript arith.R 1 + 2 # Rscript arith.R 3 - 4 # args <- commandArgs(trailingOnly = TRUE) num1 <- as.numeric(args[1]) operation <- args[2] num2 <- as.numeric(args[3]) if (operation == "+") { answer <- num1 + num2 cat(answer) } else if (operation == "-") { answer <- num1 - num2 cat(answer) } else { stop("Invalid input. Use + for addition or - for subtraction.") } } main()
- What goes wrong if you try to add multiplication using
*to the program?Solution
An error message is returned due to “invalid input.” This is likely because ‘*’ has a special meaning in the shell, as a wildcard.
- Using the function
list.filesintroduced in a previous lesson, write a command-line program calledfind-pattern.Rthat lists all the files in the current directory that contain a specific pattern:# For example, searching for the pattern "print-args" returns the two scripts we wrote earlier Rscript find-pattern.R print-argsprint-args-trailing.R print-args.RSolution
cat find-pattern.Rmain <- function() { # Finds all files in the current directory that contain a given pattern. # # Takes one argument: the pattern to be searched. # # Ex. usage: # Rscript find-pattern.R csv # args <- commandArgs(trailingOnly = TRUE) pattern <- args[1] files <- list.files(pattern = pattern) cat(files, sep = "\n") } main()
Handling Multiple Files
The next step is to teach our program how to handle multiple files. Since 60 lines of output per file is a lot to page through, we’ll start by using three smaller files, each of which has three days of data for two patients. Let’s investigate them from the Unix Shell:
ls data/small-*.csv
data/small-01.csv
data/small-02.csv
data/small-03.csv
cat data/small-01.csv
0,0,1
0,1,2
Rscript readings-02.R data/small-01.csv
0.3333333
1
Using small data files as input also allows us to check our results more easily: here, for example, we can see that our program is calculating the mean correctly for each line, whereas we were really taking it on faith before. This is yet another rule of programming: test the simple things first.
We want our program to process each file separately, so we need a loop that executes once for each filename.
If we specify the files on the command line, the filenames will be returned by commandArgs(trailingOnly = TRUE).
We’ll need to handle an unknown number of filenames, since our program could be run for any number of files.
The solution is to loop over the vector returned by commandArgs(trailingOnly = TRUE).
Here’s our changed program, which we’ll save as readings-03.R:
main <- function() {
args <- commandArgs(trailingOnly = TRUE)
for (filename in args) {
dat <- read.csv(file = filename, header = FALSE)
mean_per_patient <- apply(dat, 1, mean)
cat(mean_per_patient, sep = "\n")
}
}
main()
and here it is in action:
Rscript readings-03.R data/small-01.csv data/small-02.csv
0.3333333
1
13.66667
11
Note: at this point, we have created three versions of our script called readings-01.R, readings-02.R, and readings-03.R.
We wouldn’t do this in real life: instead, we would have one file called readings.R that we committed to version control every time we got an enhancement working.
For teaching, though, we need all the successive versions side by side.
A Command Line Program with Arguments
Write a program called
check.Rthat takes the names of one or more inflammation data files as arguments and checks that all the files have the same number of rows and columns. What is the best way to test your program?Solution
cat check.Rmain <- function() { # Checks that all csv files have the same number of rows and columns. # # Takes multiple arguments: the names of the files to be checked. # # Ex. usage: # Rscript check.R inflammation-* # args <- commandArgs(trailingOnly = TRUE) first_file <- read.csv(args[1], header = FALSE) first_dim <- dim(first_file) # num_rows <- dim(first_file)[1] # nrow(first_file) # num_cols <- dim(first_file)[2] # ncol(first_file) for (filename in args[-1]) { new_file <- read.csv(filename, header = FALSE) new_dim <- dim(new_file) if (new_dim[1] != first_dim[1] | new_dim[2] != first_dim[2]) { cat("Not all the data files have the same dimensions.") } } } main()
Handling Command-Line Flags
The next step is to teach our program to pay attention to the --min, --mean, and --max flags.
These always appear before the names of the files, so let’s save the following in readings-04.R:
main <- function() {
args <- commandArgs(trailingOnly = TRUE)
action <- args[1]
filenames <- args[-1]
for (f in filenames) {
dat <- read.csv(file = f, header = FALSE)
if (action == "--min") {
values <- apply(dat, 1, min)
} else if (action == "--mean") {
values <- apply(dat, 1, mean)
} else if (action == "--max") {
values <- apply(dat, 1, max)
}
cat(values, sep = "\n")
}
}
main()
And we can confirm this works by running it from the Unix Shell:
Rscript readings-04.R --max data/small-01.csv
1
2
but there are several things wrong with it:
-
mainis too large to read comfortably. -
If
actionisn’t one of the three recognized flags, the program loads each file but does nothing with it (because none of the branches in the conditional match). Silent failures like this are always hard to debug.
This version pulls the processing of each file out of the loop into a function of its own.
It also uses stopifnot to check that action is one of the allowed flags before doing any processing, so that the program fails fast. We’ll save it as readings-05.R:
main <- function() {
args <- commandArgs(trailingOnly = TRUE)
action <- args[1]
filenames <- args[-1]
stopifnot(action %in% c("--min", "--mean", "--max"))
for (f in filenames) {
process(f, action)
}
}
process <- function(filename, action) {
dat <- read.csv(file = filename, header = FALSE)
if (action == "--min") {
values <- apply(dat, 1, min)
} else if (action == "--mean") {
values <- apply(dat, 1, mean)
} else if (action == "--max") {
values <- apply(dat, 1, max)
}
cat(values, sep = "\n")
}
main()
This is four lines longer than its predecessor, but broken into more digestible chunks of 8 and 12 lines.
Parsing Command-Line Flags
R has a package named argparse that helps handle complex command-line flags (it utilizes a Python module of the same name). We will not cover this package in this lesson but when you start writing programs with multiple parameters you’ll want to read through the package’s vignette.
Shorter Command Line Arguments
Rewrite this program so that it uses
-n,-m, and-xinstead of--min,--mean, and--maxrespectively. Is the code easier to read? Is the program easier to understand?Separately, modify the program so that if no action is specified (or an incorrect action is given), it prints a message explaining how it should be used.
Solution
cat readings-short.Rmain <- function() { args <- commandArgs(trailingOnly = TRUE) action <- args[1] filenames <- args[-1] stopifnot(action %in% c("-n", "-m", "-x")) for (f in filenames) { process(f, action) } } process <- function(filename, action) { dat <- read.csv(file = filename, header = FALSE) if (action == "-n") { values <- apply(dat, 1, min) } else if (action == "-m") { values <- apply(dat, 1, mean) } else if (action == "-x") { values <- apply(dat, 1, max) } cat(values, sep = "\n") } main()The program is neither easier to read nor easier to understand due to the ambiguity of the argument names.
cat readings-usage.Rmain <- function() { args <- commandArgs(trailingOnly = TRUE) action <- args[1] filenames <- args[-1] if (!(action %in% c("--min", "--mean", "--max"))) { usage() } else if (length(filenames) == 0) { process(file("stdin"), action) } else { for (f in filenames) { process(f, action) } } } process <- function(filename, action) { dat <- read.csv(file = filename, header = FALSE) if (action == "--min") { values <- apply(dat, 1, min) } else if (action == "--mean") { values <- apply(dat, 1, mean) } else if (action == "--max") { values <- apply(dat, 1, max) } cat(values, sep = "\n") } usage <- function() { cat("usage: Rscript readings-usage.R [--min, --mean, --max] filenames", sep = "\n") } main()
Handling Standard Input
The next thing our program has to do is read data from standard input if no filenames are given so that we can put it in a pipeline, redirect input to it, and so on.
Let’s experiment in another script, which we’ll save as count-stdin.R:
lines <- readLines(con = file("stdin"))
count <- length(lines)
cat("lines in standard input: ")
cat(count, sep = "\n")
This little program reads lines from the program’s standard input using file("stdin").
This allows us to do almost anything with it that we could do to a regular file.
In this example, we passed it as an argument to the function readLines, which stores each line as an element in a vector.
Let’s try running it from the Unix Shell as if it were a regular command-line program:
Rscript count-stdin.R < data/small-01.csv
lines in standard input: 2
Note that because we did not specify sep = "\n" when calling cat, the output is written on the same line.
A common mistake is to try to run something that reads from standard input like this:
Rscript count-stdin.R data/small-01.csv
i.e., to forget the < character that redirect the file to standard input.
In this case, there’s nothing in standard input, so the program waits at the start of the loop for someone to type something on the keyboard.
We can type some input, but R keeps running because it doesn’t know when the standard input has ended.
If you ran this, you can pause R by typing Ctrl+Z (technically it is still paused in the background; if you want to fully kill the process type kill %; see bash manual for more information).
We now need to rewrite the program so that it loads data from file("stdin") if no filenames are provided.
Luckily, read.csv can handle either a filename or an open file as its first parameter, so we don’t actually need to change process.
That leaves main, which we’ll update and save as readings-06.R:
main <- function() {
args <- commandArgs(trailingOnly = TRUE)
action <- args[1]
filenames <- args[-1]
stopifnot(action %in% c("--min", "--mean", "--max"))
if (length(filenames) == 0) {
process(file("stdin"), action)
} else {
for (f in filenames) {
process(f, action)
}
}
}
process <- function(filename, action) {
dat <- read.csv(file = filename, header = FALSE)
if (action == "--min") {
values <- apply(dat, 1, min)
} else if (action == "--mean") {
values <- apply(dat, 1, mean)
} else if (action == "--max") {
values <- apply(dat, 1, max)
}
cat(values, sep = "\n")
}
main()
Let’s try it out. Instead of calculating the mean inflammation of every patient, we’ll only calculate the mean for the first 10 patients (rows):
head data/inflammation-01.csv | Rscript readings-06.R --mean
5.45
5.425
6.1
5.9
5.55
6.225
5.975
6.65
6.625
6.525
And now we’re done: the program now does everything we set out to do.
Implementing
wcin RWrite a program called
line-count.Rthat works like the Unixwccommand:
- If no filenames are given, it reports the number of lines in standard input.
- If one or more filenames are given, it reports the number of lines in each, followed by the total number of lines.
Solution
cat line-count.Rmain <- function() { args <- commandArgs(trailingOnly = TRUE) if (length(args) > 0) { total_lines <- 0 for (filename in args) { input <- readLines(filename) num_lines <- length(input) cat(filename) cat(" ") cat(num_lines, sep = "\n") total_lines <- total_lines + num_lines } if (length(args) > 1) { cat("Total ") cat(total_lines, sep = "\n") } } else { input <- readLines(file("stdin")) num_lines <- length(input) cat(num_lines, sep = "\n") } } main()
Key Points
Use
commandArgs(trailingOnly = TRUE)to obtain a vector of the command-line arguments that a program was run with.Avoid silent failures.
Use
file("stdin")to connect to a program’s standard input.Use
cat(vec, sep = " ")to write the elements ofvecto standard output, one per line.
Writing Good Software
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How can I write software that other people can use?
Objectives
Describe best practices for writing R and explain the justification for each.
Structure your project folder
Keep your project folder structured, organized and tidy, by creating subfolders for your code files, manuals, data, binaries, output plots, etc. It can be done completely manually, or with the help of RStudio’s New Project functionality, or a designated package, such as ProjectTemplate.
Tip: ProjectTemplate - a possible solution
One way to automate the management of projects is to install the third-party package,
ProjectTemplate. This package will set up an ideal directory structure for project management. This is very useful as it enables you to have your analysis pipeline/workflow organised and structured. Together with the default RStudio project functionality and Git you will be able to keep track of your work as well as be able to share your work with collaborators.
- Install
ProjectTemplate.- Load the library
- Initialise the project:
install.packages("ProjectTemplate") library("ProjectTemplate") create.project("../my_project_2", merge.strategy = "allow.non.conflict")For more information on ProjectTemplate and its functionality visit the home page ProjectTemplate
Make code readable
The most important part of writing code is making it readable and understandable. You want someone else to be able to pick up your code and be able to understand what it does: more often than not this someone will be you 6 months down the line, who will otherwise be cursing past-self.
Documentation: tell us what and why, not how
When you first start out, your comments will often describe what a command does, since you’re still learning yourself and it can help to clarify concepts and remind you later. However, these comments aren’t particularly useful later on when you don’t remember what problem your code is trying to solve. Try to also include comments that tell you why you’re solving a problem, and what problem that is. The how can come after that: it’s an implementation detail you ideally shouldn’t have to worry about.
Keep your code modular
Our recommendation is that you should separate your functions from your analysis
scripts, and store them in a separate file that you source when you open the R
session in your project. This approach is nice because it leaves you with an
uncluttered analysis script, and a repository of useful functions that can be
loaded into any analysis script in your project. It also lets you group related
functions together easily.
Break down problem into bite size pieces
When you first start out, problem solving and function writing can be daunting tasks, and hard to separate from code inexperience. Try to break down your problem into digestible chunks and worry about the implementation details later: keep breaking down the problem into smaller and smaller functions until you reach a point where you can code a solution, and build back up from there.
Know that your code is doing the right thing
Make sure to test your functions!
Don’t repeat yourself
Functions enable easy reuse within a project. If you see blocks of similar lines of code through your project, those are usually candidates for being moved into functions.
If your calculations are performed through a series of functions, then the project becomes more modular and easier to change. This is especially the case for which a particular input always gives a particular output.
Remember to be stylish
Apply consistent style to your code.
Key Points
Keep your project folder structured, organized and tidy.
Document what and why, not how.
Break programs into short single-purpose functions.
Write re-runnable tests.
Don’t repeat yourself.
Be consistent in naming, indentation, and other aspects of style.